57 gesichtete, geschützte Fragmente: Plagiat
| [1.] Saa/Fragment 029 09 - Diskussion Bearbeitet: 17. May 2015, 16:02 Schumann Erstellt: 6. September 2014, 20:18 (Hindemith) | Fragment, Gesichtet, Morin 2002, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 29, Zeilen: 9-16 |
Quelle: Morin 2002 Seite(n): 2, 3, Zeilen: 2: 3ff; 3: 1ff |
|---|---|

Figure 2.6: Electronic radiology practice and its components Image acquisition combined with image management and interpretation is generally considered together as PACS. The communication of the PACS with the other electronic systems in the radiology department, i.e. Radiology Information System, and institution, i.e. Hospital Information System is essential to fully realize the implementation and benefits afforded by automation. Even though the effect of PACS is far greater outside the radiology department, the function of PACS within the department can be markedly different depending upon the proper design and function of these interfaces. |

Figure 1 Diagram of the electronic radiology practice and its components.
[Seite 3] department, the function of PACS within the department can be markedly different depending upon the proper design and function of these interfaces. |
Ein Verweis auf die Quelle fehlt; die Quelle weist keine Paginierung auf. |
|
| [2.] Saa/Fragment 037 12 - Diskussion Bearbeitet: 17. May 2015, 13:45 Schumann Erstellt: 8. September 2014, 17:26 (Graf Isolan) | Fragment, Gesichtet, Microsoft Healthcare 2003, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 37, Zeilen: 12-17 |
Quelle: Microsoft Healthcare 2003 Seite(n): 1, Zeilen: 2-5 |
|---|---|
| 2.8.4 What is e-Healthcare
Healthcare is a vital part of the economy and important to every citizen, and yet the healthcare economy has not benefited from the technology revolution that is fundamentally changing whole industries. Leading software companies i.e. Microsoft and IBM believe that the present time is right for the [sic] technology to have a dramatic and fundamental impact in improving healthcare delivery, payment and personal health management. |
Introduction
Healthcare is a vital part of the economy and important to every citizen. Yet the healthcare economy has not benefited from the technology revolution that is fundamentally changing whole industries. Microsoft Corp. believes the time is right for technology to have a dramatic and fundamental impact in improving healthcare delivery, payment and personal health management. |
Ohne Hinweis auf eine Übernahme. Interessant: Die Firmenphilosophie, die in der Vorlage (natürlich) explizit Microsoft zugeordnet ist ("The information contained in this document represents the current view of Microsoft on the issues discussed as of the date of publication."), wird vom Verfasser kurzerhand auf IBM und andere "Leading software companies" ausgedehnt. |
|
| [3.] Saa/Fragment 023 08 - Diskussion Bearbeitet: 17. May 2015, 13:38 Schumann Erstellt: 6. September 2014, 16:25 (Hindemith) | BauernOpfer, Bishaj 2007, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 23, Zeilen: 8-45 |
Quelle: Bishaj 2007 Seite(n): 2, 3, Zeilen: 2: r. Spalte: 31ff; 3: l. Spalte: 1ff |
|---|---|
| 2.5.1 Universal Plug and Play
Universal Plug and Play (UPnP) [56] is an industry initiative by Mirosoft [sic] to provide simple, robust, peer-to-peer connectivity among devices and PCs. Plug and Play (PnP) made it easier to setup, configure, and add peripherals to a PC, while the purpose of UPnP is to extend this simplicity throughout the network, enabling discovery and control of devices. Its target is zero configuration, invisible networking, as well as automatic discovery for the devices of many vendors. UPnP encompasses many existing, as well as new scenarios, such as home automation, printing, audio/video entertainment, kitchen appliances, etc., and is independent of operating systems, programming languages, or physical media. The basic components of a UPnP network are: devices, services, and control points. A UPnP device contains services and nested devices. An XML device description document is hosted by each device; this document lists the set of services and properties of the device. A service is the smallest unit of control in UPnP. It is described in the XML document of the device, which also contains a pointer to the service description. A service consists of a state table, a control server, and an event server. The state table controls the state of the service through state variables. The control server updates the state according to action requests. The event server notifies interested subscribers when the service state changes. A controller is capable of discovering and controlling other devices. For true peer-to-peer functionality, devices should incorporate control point functionality. There is no central registry in UPnP, at least not necessarily. UPnP uses many existing, standard protocols, so that UPnP devices can fit seamlessly and without effort into the existing networks. TCP/IP is the base on which the UPnP protocols are built, as well as many protocols that go with it, such as UDP, ARP, DHCP and DNS. HTTP is a core part of UPnP and its aspects are based on HTTP or its variants. The Simple Service Discovery Protocol (SSDP) defines how to find network services. It is both for control points to locate services on the network, as well as for devices to announce their availability. A UPnP control point, when booting up, can send a search request to discover devices and services. UPnP devices, on the other hand, listen on the multicast port. If the search criteria match, a unicast reply is sent. In the same way, a device, when plugged in, will send out multiple SSDP presence announcements. Apart from the leasing concept that UPnP also shares, SSDP provides a way for a device to notify that it is leaving the network. The Generic Event Notification Architecture (GENA) defines the concepts of subscribers and publishers of notifications. The GENA formats are used to create these announcements that are sent using SSDP. SOAPis [sic] used in UPnP to execute remote procedure calls, as well as to deliver control messages and return results or error messages to the control points. XML is used in UPnP in device and service descriptions, control [messages and eventing.] [56] UPnP Specification, http://www.upnp.org/ resources/default.asp |
[Seite 2]
2.2 UPnP UPnP [9] is an industry initiative by Mirosoft [sic] to provide simple, robust, peer-to-peer connectivity among devices and PCs. Plug and Play (PnP) made it easier to setup, configure, and add peripherals to a PC, while the purpose of UPnP is to extend this simplicity throughout the network, enabling discovery and control of devices. Its target is zero-configuration, invisible networking, as well as automatic discovery for the devices of many vendors. UPnP encompasses many existing, as well as new scenarios, such as home automation, printing, audio/video entertainment, kitchen appliances, etc. UPnP is independent of operating systems, programming languages, or physical media. The basic components of a UPnP network are: devices, services, and control points. A UPnP device contains services and nested devices. An XML device description document is hosted by each device; this document lists the set of services and properties of the device. A service is the smallest unit of control in UPnP. It is described in the XML document of the device, which also contains a pointer to the service description. A service consists of a state table, a control server, and an event server. The state table controls the state of the service through state variables. The control server updates the state according to action requests. The event server notifies interested subscribers when the service state changes. A controller is capable of discovering and controlling other devices. For true peer-to-peer functionality, devices should incorporate control point functionality. There [Seite 3] is no central registry in UPnP, at least not necessarily [3, 5]. UPnP uses many existing, standard protocols, so that UPnP devices can fit seamlessly and without effort into the existing networks [9]. TCP/IP is the base on which the UPnP protocols are built, as well as many protocols that go with it, such as UDP, ARP, DHCP and DNS. HTTP is a core part of UPnP. All UPnP aspects are based on HTTP or its variants. The Simple Service Discovery Protocol (SSDP) defines how to find network services [9]. It is both for control points to locate services on the network, as well as for devices to announce their availability. A UPnP control point, when booting up, can send a search request to discover devices and services. UPnP devices, on the other hand, listen on the multicast port. If the search criteria match, a unicast reply is sent. In the same way, a device, when plugged in, will send out multiple SSDP presence announcements. Apart from the leasing concept that UPnP also shares, SSDP provides a way for a device to notify that it is leaving the network. The Generic Event Notification Architecture (GENA) defines the concepts of subscribers and publishers of notifications. The GENA formats are used to create these announcements that are sent using SSDP [14]. Simple Object Access Protocol (SOAP) [13] is used in UPnP to execute remote procedure calls, as well as to deliver control messages and return results or error messages to the control points. XML is used in UPnP in device and service descriptions, control messages and eventing. [3] Adrian Friday, Nigel Davies, Nat Wallbank, Elaine Catterall and Stephen Pink. Supporting Service Discovery, Querying and Interaction in Ubiquitous Computing Environments. Wireless Networks 10, 631-641, 2004. [5] Choonhwa Lee and Sumi Helal. Protocols for Service Discovery in Dynamic and Mobile Networks. International Journal of Computer Research, 2002. [9] UPnP Device Architecture. http://www.upnp.org/download/ UPnPDA10\_20000613.htm,09 April 2007. [13] W3C Recommendation. 24 June 2003. http://www.w3.org/TR/soap12-part1/, 9 April 2007. [14] Universal Plug and Play in Windows XP. http://www.microsoft.com/technet/prodtechnol/ winxppro/evaluate/upnpxp.mspx, 9 April 2007. |
Ein Verweis auf die Quelle findet sich am Anfang des Kapitels. Eine wörtliche Übernahme des gesamten Kapitels wird durch diesen aber in keiner Weise gekennzeichnet. Aus Microsoft wird in beiden Texten "Mirosoft". |
|
| [4.] Saa/Fragment 023 01 - Diskussion Bearbeitet: 17. May 2015, 09:54 Hindemith Erstellt: 23. November 2014, 06:38 (Hindemith) | BauernOpfer, Fragment, Gesichtet, Klusch 2008, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 23, Zeilen: 1-4 |
Quelle: Klusch 2008 Seite(n): 57, Zeilen: 1 ff. |
|---|---|
| [WSML-Full shall] unify the DL and LP paradigms as a superset of FOL with non-monotonic extensions to support nonmonotonic negation of WSML-Rule via Default Logic, Circumscription or Autoepistemic Logic. However, neither syntax nor semantics of WSML-Full have been completely defined yet. | 5. WSML-Full shall unify the DL and LP paradigms as a superset of FOL with non-monotonic extensions to support the nonmonotonic negation of WSML-Rule via Default Logic, Circumscription or Autoepistemic Logic. However, neither syntax nor semantics of WSML-Full have been completely defined yet. |
Fortsetzung von Saa/Fragment 022 26. Ohne direkten Hinweis auf eine Übernahme. Auf Seite 20 (Z. 4-6) wird eine von Matthias Klusch verfasste Quelle erwähnt: "In the following sections, we briefly describe these approaches by taking the text snippets from [43], and refer the reader to this for detailed description." [43] Matthias Klusch, On Agent-Based Semantic Service Coordination, Cumulative Habilitation Script 2008. |
|
| [5.] Saa/Fragment 047 04 - Diskussion Bearbeitet: 17. May 2015, 09:54 Hindemith Erstellt: 9. September 2014, 11:09 (Hindemith) | BauernOpfer, Fragment, Gesichtet, ITEA 2007, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 47, Zeilen: 4-14 |
Quelle: ITEA 2007 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| The SODA (Service Oriented Device and Delivery Architecture) project [15], an FP6 European Commission funded Integrated Project, targets to create a service-oriented ecosystem2, built on top of the foundations laid by the groundbreaking SIRENA [72] framework for high-level device communications based on the Service-Oriented Architecture (SOA) paradigm. The SODA project implements a comprehensive, scale-able and easy-to-deploy SOA ecosystem on industry-favorite platforms, supported by wired & wireless communications. The service infrastructure for real-time embedded devices used as a foundation for the SODA project is defined in a platform-, language- and network-neutral way, applicable to a wide variety of networked devices for diverse applications in domains like industrial automation, automotive electronics, home & building automation, telecommunications, medical instrumentation, etc.
2 An Ecosystem is a combination of all the living (organisms or actors) and non-living elements (environment) of a complex area organized in a perfect harmony functioning as a whole. In the context of the SODA project, the living elements are similar to the run-time components of a particular SODA system, and the non-living elements are similar to the tools used during design, deployment, etc. [15] The ITEA SODA Project; http://www.soda-itea.org/ Home/default.html [72] The ITEA SIRENA Project; http://www.sirena-itea.org/ Sirena/Home.htm |
The SODA project is a European R&D project, part of the ITEA programme, itself a "cluster" organisation within the Eureka framework.
The objective of the SODA project is to create a service-oriented ecosystem built on top of the foundations laid by the groundbreaking SIRENA framework for high-level communications between devices based on the service-oriented architecture (SOA) paradigm. The SIRENA project has played a pioneering role by applying the SOA paradigm to communications and interworking between components at the device level. This service infrastructure for real-time embedded devices, used as a foundation for the SODA project, is defined in a platform-, language- and network-neutral way, applicable to a wide variety of networked devices for diverse applications in domains like industrial automation, automotive electronics, home and building automation, telecommunications, telemetry, medical instrumentation, etc. |
Es gibt einen Verweis auf die Quelle. Dieser kennzeichnet aber nicht die z.T. wörtlichen Zitate. |
|
| [6.] Saa/Fragment 043 04 - Diskussion Bearbeitet: 17. May 2015, 09:54 Hindemith Erstellt: 9. September 2014, 10:36 (Hindemith) | BauernOpfer, Fragment, Gesichtet, SMWFragment, Saa, Sarnovsky et al 2007, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 43, Zeilen: 4-32 |
Quelle: Sarnovsky et al 2007 Seite(n): 1, 2, Zeilen: 1: 34 ff.; 2: 1 ff. |
|---|---|
| The HYDRA1, an FP6 European Commission funded Integrated Project, addresses the problem that is frequently faced by producers of devices and components - the need for (which is actually becoming a trend) networking the products available on the market in order to provide higher value-added solutions for their customers [17]. This requirement is implied by citizen centered demands requiring intelligent solutions, where the complexity is hidden behind user-friendly interfaces to promote inclusion. The vision of the HYDRA project is ambitious: "To create the most widely deployed middleware for intelligent networked embedded systems that will allow producers to develop cost-effective and innovative embedded applications for new and already existing devices".
HYDRA develops a middleware based on a Service-Oriented Architecture (SOA), to which the underlying communication layer is transparent. Hydra middleware is designed to run on a variety of stationary and mobile devices, and includes support for distributed as well as centralized architectures, security and trust, reflective properties and model-driven development of applications. It is deployable on both new and existing networks of distributed wireless and wired devices, which operate with limited resources in terms of computing power, energy and memory usage. It allows for secure, trustworthy, and fault tolerant applications through the use of novel distributed security and social trust components and advanced Grid technologies. The embedded and mobile Service-Oriented Architecture provides interoperable access to data, information and knowledge across heterogeneous platforms, including Web Services, and support true ambient intelligence for ubiquitous networked devices. Furthermore HYDRA develops a Software Development Kit (SDK), which will be used by developers to develop innovative Model-Driven applications using the Hydra middleware, where middleware and connected devices enable the developers to implement applications that depend on and adapt to context information. In particular, the developers stress the acquisition and management of spatial context information that allows for locating devices attached to the system and for the positioning of people and assets. The HYDRA project validates the middleware, the SDK toolkit in real end-user scenarios in three user domains, namely Building Automation, Healthcare, and Agriculture. 1 http://www.hydramiddleware.eu [17] Sarnovsky, M., Butka, P., Kostelnik, P., Lackova, D.; HYDRA - Network Embedded System Middleware for Ambient Intelligent Devices, In: ICCC' 2007: Proceedings of 8th International Carpathian Control Conference, Strbska Pleso, Slovak Republic, May 24-27 (2007) 611-614 |
The HYDRA project is addressing the problem, which is frequently faced by producers of devices and components - the need for (which is actually becoming a trend) networking the products available on the market in order to provide higher value-added solutions for their customers. This requirement is implied by citizen centred demands requiring intelligent
[Seite 2] solutions, where the complexity is hidden behind user-friendly interfaces to promote inclusion. The vision of the HYDRA project is ambitious: To create the most widely deployed middleware for intelligent networked embedded systems that will allow producers to develop cost-effective and innovative embedded applications for new and already existing devices. [Seite 3] Hydra will develop middleware based on a Service-oriented Architecture (SOA), to which the underlying communication layer is transparent. Hydra middleware will be designed to run on a variety of stationary and mobile devices. The middleware will include support for distributed as well as centralised architectures, security and trust, reflective properties and model-driven development of applications. It will be deployable on both new and existing networks of distributed wireless and wired devices, which operate with limited resources in terms of computing power, energy and memory usage. It will allow for secure, trustworthy, and fault tolerant applications through the use of novel distributed security and social trust components and advanced Grid technologies. The embedded and mobile Service-oriented Architecture will provide interoperable access to data, information and knowledge across heterogeneous platforms, including web services, and support true ambient intelligence for ubiquitous networked devices. Furthermore Hydra will develop a Software Development Kit (SDK), which will be used by developers to develop innovative Model-Driven applications using the Hydra middleware. Middleware and connected devices should enable developers to implement applications that depend on and adapt to context information. In particular, the developers stressed the acquisition and management of spatial context information that allows for locating devices attached to the system and for the positioning of people and assets. The Hydra project will validate the middleware, the SDK toolkit in real end-user scenarios in three user domains. |
Die Quelle ist angegeben, nicht aber, dass die gesamte hier dokumentierte Passage aus ihr stammt. |
|
| [7.] Saa/Fragment 022 26 - Diskussion Bearbeitet: 17. May 2015, 09:54 Hindemith Erstellt: 7. September 2014, 23:53 (Graf Isolan) | BauernOpfer, Fragment, Gesichtet, Klusch 2008, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 22, Zeilen: 26-33, 37-47 |
Quelle: Klusch 2008 Seite(n): 55, 56, Zeilen: 55: 16-19, 23-30; 56: 1ff |
|---|---|
| WSML allows to describe a SWS in terms of its functionality (service capability), imported ontologies, and the interface through which it can be accessed for orchestration and choreography. The syntax of WSML is mainly derived from F-Logic extended with more verbose keywords (e.g., "hasValue" for ->, "p memberOf T" for p:T etc.), and has a normative human-readable syntax, as well as an XML and RDF syntax for exchange between machines. WSML comes in five variants with respect to the logical expressions allowed to describe the semantics of service and goal description elements, namely WSMLCore, WSML-DL, WSML-Flight, WSML-Rule and WSML-Full.
Though WSML has a special focus on annotating Semantic Web Services like OWLS, it tries to cover more representational aspects from knowledge representation and reasoning under both classical FOL and nonmononotic LP semantics. For example, WSML-DL is a decidable variant of F-Logic(FO) with expressivity close to the description logic SHOIN(D), that is the variant OWL-DL of the standard ontology Web language OWL. WSML-Flight is a decidable Datalog variant of F-Logic(LP) (functionfree, non-recursive and DL-safe Datalog rules) with (nonmonotonic) default negation under perfect model semantics of locally stratified F-Logic programs with ground entailment. WSML-Rule is a fully-edged logic programming language with function symbols, arbitrary rules with inequality and nonmontonic negation, and meta-modeling elements such as treating concepts as instances, but does not feature existentials, strict (monotonic) negation, and equality reasoning. The semantics of WSML-Rule is defined through a mapping to undecidable (nonmonotonic, recursive) F-Logic(LP) variant with inequality and default negation under well-founded semantics [368]. |
WSML is particularly designed for describing a Semantic Web Service in terms of its functionality (service capability), imported ontologies in WSML, and the interface through which it can be accessed for the purpose of orchestration and choreography. [...]
[...] The syntax of WSML is mainly derived from F-Logic extended with more verbose keywords and varies with respect to the logical expressions allowed to describe the semantics of service and goal description elements. WSML has a normative human-readable syntax, as well as an XML and an RDF syntax for exchange between machines. The language comes in different variants each grounded on a particular logic with different expressivity and computational complexity, namely, DL (WSML-DL), LP (WSML-Flight, WSML-Rule), and nonmonotonic logic (WSML-Full) (cf. Figure 3.10). [Seite 56] 2. WSML-DL is a decidable DL variant of F-Logic, extending WSML-Core to SHIQ(D) that subsumes SHIF(D) underlying OWL-Lite and is subsumed by SHOIN(D) underlying OWL-DL. The model-theoretic semantics of WSMLDL generalizes that of WSML-Core and is defined through a mapping to function-free PL1 with equality. WSML-DL provides only limited modeling of restrictions (no closed world constraints) and no arbitrary rules. 3. WSML-Flight is a decidable Datalog variant of F-Logic (function-free, nonrecursive and DL-safe rules). Its modeling primitives allow to specify different aspects of attributes, such as value constraints and integrity constraints (via built-ins), while safe Datalog rules extended with inequality and (locally) stratified negation allow efficient decidable reasoning. In other words, in WSML-FLight, concepts, instances and attributes are interpreted as objects in F-Logic with (nonmonotonic) default negation under perfect model semantics [22] of locally stratified F-Logic programs with ground entailment. 4. WSML-Rule extends WSML-Flight to a fully-fledged LP language, i.e. with function symbols and allowing arbitrary, unsafe rules with inequality and unstratified negation. It also provides meta modeling such as treating concepts as instances, but does not feature existentials, classical (monotonic) negation, and equality reasoning. The semantics of WSML-Rule is defined in the same way as WSML-Flight but through a mapping to full LP, that is to the Horn fragment of F-Logic extended with inequality and default negation under well-founded semantics [26] in the body of the rule instead of through a mapping to Datalog. In brief, the semantics of WSML-Rule bases on the well-founded semantics applied to the LP fragment of F-Logic [27]. [27] T. Di Noia, E. Di Sciascio, F.M. Donini: Semantic Matchmaking as Non-Monotonic Reasoning: A Description Logic Approach. Artificial Intelligence Research (JAIR), 29:269–307, 2007. |
Einen Eintrag "[368]" gibt es im Literaturverzeichnis nicht. Ohne direkten Hinweis auf eine Übernahme. Auf Seite 20 (Z. 4-6) wird eine von Matthias Klusch verfasste Quelle erwähnt: "In the following sections, we briefly describe these approaches by taking the text snippets from [43], and refer the reader to this for detailed description." [43] Matthias Klusch, On Agent-Based Semantic Service Coordination, Cumulative Habilitation Script 2008. Mit Blick hierauf ist auch eine Einordnung als kW denkbar. |
|
| [8.] Saa/Fragment 020 07 - Diskussion Bearbeitet: 17. May 2015, 09:19 SleepyHollow02 Erstellt: 7. September 2014, 19:50 (Graf Isolan) | BauernOpfer, Fragment, Gesichtet, Klusch 2008, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 20, Zeilen: 7-43 |
Quelle: Klusch 2008 Seite(n): 43, 44, 45, Zeilen: 43:26-34 - 44:1-25.37-38 - 45:1-2.9ff |
|---|---|
| SAWSDL
The standard language WSDL for Web Services operates at the mere syntactic level as it lacks any declarative semantics needed to meaningfully represent and reason upon them by means of logical inferencing. In a first response to this problem, the W3C Working Group on Semantic Annotations for WSDL and XML Schema (SAWSDL) [48] developed mechanisms with which semantic annotations can be added to WSDL components. Unlike OWL or WSML, SAWSDL does not specify a language for representing formal ontologies but provides mechanisms by which ontological concepts that are defined outside WSDL service documents can be referenced to semantically annotate WSDL description elements. Based on its predecessor and W3C member submission WSDL-S [51] in 2005, the key design principles for SAWSDL are that (a) the specification enables semantic annotations of Web Services using and building on the existing extensibility framework of WSDL; (b) it is agnostic to semantic (ontology) representation languages; and (c) it enables semantic annotations for Web Services not only for discovering Web Services but also for invoking them (their grounding). Based on these design principles, SAWSDL defines the following three new extensibility attributes to WSDL 2.0 elements for their semantic annotation: • An extension attribute, named modelReference, to specify the association between a WSDL component and a concept in some semantic (domain) model. This modelReference attribute is used to annotate XML Schema complex type definitions, simple type definitions, element declarations, and attribute declarations as well as WSDL interfaces, operations, and faults. • Two extension attributes, named liftingSchemaMapping and loweringSchema-Mapping, that are added to XML Schema element declarations, complex type definitions and simple type definitions for specifying mappings between semantic data in the domain referenced by modelReference and XML. These mappings can be used during service invocation. One problem with SAWSDL is that it comes as a mere syntactic extension of WSDL, without any formal semantics. In opposite to OWL-S and (in part) WSML, there is no defined formal grounding of neither the XML-based WSDL service components nor the referenced external metadata sources (via modelReference). Another problem with SAWSDL today is its very limited software support. Notable exceptions are the implemented SAWSDL service discovery and composition planning means of the METEOR-S framework [52]. However, the recent announcement of SAWSDL as a W3C recommendation not only supports a standardized evolution of the W3C Web Service framework in principle (rather than a revolutionary technology switch to far more advanced technologies like OWL-S or WSML) but will push software development in support of SAWSDL and reinforce research on refactoring these frameworks with respect to SAWSDL. [51] Web Service Semantics (WSDL-S); http://www.w3.org/Submission/WSDL-S/ [52] METEOR-S: Semantic Web Services and Process; http://lsdis.cs.uga.edu/projects/meteor-s/ |
[Seite 43]
3.3 SAWSDL The standard language WSDL for Web Services operates at the mere syntactic level as it lacks any declarative semantics needed to meaningfully represent and reason upon them by means of logical inferencing. In a first response to this problem, the W3C Working Group on Semantic Annotations for WSDL and XML Schema (SAWSDL) developed mechanisms with which semantic annotations can be added to WSDL components. The SAWSDL specification became a W3C candidate recommendation on January 26, 20072, and eventually a W3C recommendation on August 28, 2007. [Seite 44] 3.3.1 Annotating WSDL Components Unlike OWL-S or WSML, SAWSDL does not specify a new language or toplevel ontology for semantic service description but simply provides mechanisms by which ontological concepts that are defined outside WSDL service documents can be referenced to semantically annotate WSDL description elements. Based on its predecessor and W3C member submission WSDL-S3 in 2005, the key design principles for SAWSDL are that (a) the specification enables semantic annotations of Web Services using and building on the existing extensibility framework of WSDL; (b) it is agnostic to semantic (ontology) representation languages; and (c) it enables semantic annotations for Web Services not only for discovering Web Services but also for invoking them. Based on these design principles, SAWSDL defines the following three new extensibility attributes to WSDL 2.0 elements for their semantic annotation: • An extension attribute, named modelReference, to specify the association between a WSDL component and a concept in some semantic (domain) model. This modelReference attribute is used to annotate XML Schema complex type definitions, simple type definitions, element declarations, and attribute declarations as well as WSDL interfaces, operations, and faults. Each modelReference identifies the concept in a semantic model that describes the element to which it is attached. • Two extension attributes (liftingSchemaMapping and loweringSchema-Mapping) are added to the set of XML Schema element declarations, complex type definitions and simple type definitions. Both allow to specify mappings between semantic data in the domain referenced by modelReference and XML, which can be used during service invocation. [...] 3.3.2 Limitations Major critic of SAWSDL is that it comes, as a mere syntactic extension of WSDL, without any formal semantics. In contrast to OWL-S and (in part) WSML, there is [Seite 45] no defined formal grounding of neither the XML-based WSDL service components nor the referenced external metadata sources (via modelReference). [...] Another problem with SAWSDL today is its –apart from the METEOR-S framework by the developers of SAWSDL (WSDL-S) and related ongoing development efforts at IBM– still very limited software support compared to the considerable investments made in research and development of software for more advanced frameworks like OWL-S and WSMO world wide. However, the recent announcement of SAWSDL as a W3C recommendation does not only support a standardized evolution of the W3C Web Service framework in principle (rather than a revolutionary technology switch to far more advanced technologies like OWL-S or WSML) but certainly will push software development in support of SAWSDL and reinforce research on refactoring these frameworks with respect to SAWSDL. |
Ohne direkten Hinweis auf eine Übernahme. Auf Seite 20 (Z. 4-6) wird eine von Matthias Klusch verfasste Quelle erwähnt: "In the following sections, we briefly describe these approaches by taking the text snippets from [43], and refer the reader to this for detailed description. [43] Matthias Klusch, On Agent-Based Semantic Service Coordination, Cumulative Habilitation Script 2008." Hier handelt es sich aber um mehr als die Übernahme von "text snippets". Auch ist es fraglich, ob eine so generelle Quellenangabe die nachfolgenden wörtlichen Übernahmen ausreichend kennzeichnet. |
|
| [9.] Saa/Fragment 012 02 - Diskussion Bearbeitet: 16. May 2015, 21:27 Hindemith Erstellt: 3. January 2015, 12:15 (Graf Isolan) | Fragment, Gesichtet, Gutierrez-Carreon et al 2008, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 12, Zeilen: 2-5 |
Quelle: Gutierrez-Carreon et al 2008 Seite(n): 42, Zeilen: 16ff |
|---|---|
| Simple Object Access Protocol (SOAP)
SOAP [33] is a standard that represents a lightweight envelope containing the message payload as it moves between service producers and consumers. It is an XML-based standard that describes the contents of a message and how to process it, and offers a transport binding for exchanging messages. [33] SOAP 1.2 Part 1, W3C Working Draft; http://www.w3.org/TR/soap12-part1/ |
SOAP: Simple Object Access Protocol (SOAP) [15] is a standard that represents a lightweight "envelope" containing the message payload as it moves between service producers and consumers. It is an XML-based standard that describes the contents of a message and how to process it, and offers a transport binding for exchanging messages.
[15] Simple Object Access Protocol, http://www.w3.org/TR/soap/. |
Ohne Hinweis auf eine Übernahme. Die angegebene Quelle enthält den Wortlaut nicht. |
|
| [10.] Saa/Fragment 012 18 - Diskussion Bearbeitet: 16. May 2015, 20:51 Hindemith Erstellt: 3. January 2015, 12:48 (Graf Isolan) | BauernOpfer, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, W3.org - WSDL 2001 |
|
|
|
| Untersuchte Arbeit: Seite: 12, Zeilen: 18-21, 24-34 |
Quelle: w3.org - WSDL 2001 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| Web Service Description Language (WSDL)
WSDL [34] is an XML format for describing network services as a set of endpoints operating on messages containing either document-oriented or procedure-oriented information. The operations and messages are described abstractly, and then bound to a concrete network protocol and message format to define an endpoint. [...] A WSDL document uses the following elements in the definition of network services: • Types: A container for data type definitions using some type system (such as XML Schema Definition, XSD). • Message: An abstract, typed definition of the data being communicated. • Operation: An abstract description of an action supported by the service. • Port Type: An abstract set of operations supported by one or more endpoints. • Binding: A concrete protocol and data format specification for a particular port type. • Port: A single endpoint defined as a combination of a binding and a network address. • Service: A collection of related endpoints. [34] Web Service Description Language, http://www.w3.org/TR/wsdl |
Abstract
WSDL is an XML format for describing network services as a set of endpoints operating on messages containing either document-oriented or procedure-oriented information. The operations and messages are described abstractly, and then bound to a concrete network protocol and message format to define an endpoint. [...] [...] 1. Introduction [...] [...] Hence, a WSDL document uses the following elements in the definition of network services: • Types– a container for data type definitions using some type system (such as XSD). • Message– an abstract, typed definition of the data being communicated. • Operation– an abstract description of an action supported by the service. • Port Type– an abstract set of operations supported by one or more endpoints. • Binding– a concrete protocol and data format specification for a particular port type. • Port– a single endpoint defined as a combination of a binding and a network address. • Service– a collection of related endpoints. |
Art und Umfang der (hier identischen) Übernahme bleiben ungekennzeichnet. |
|
| [11.] Saa/Fragment 015 20 - Diskussion Bearbeitet: 16. May 2015, 20:34 Hindemith Erstellt: 3. January 2015, 22:03 (Graf Isolan) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung, Zeeb et al 2007 |
|
|
|
| Untersuchte Arbeit: Seite: 15, Zeilen: 20-26 |
Quelle: Zeeb et al 2007 Seite(n): III-2 (Internetversion), Zeilen: re.Sp. 2-12 |
|---|---|
| WS-Eventing
WS-Eventing defines a protocol for managing subscriptions for a Web Services based eventing mechanism. This protocol defines three endpoints: subscriber, event source and subscription manager. Subscribers request subscriptions on behalf of event sinks to receive events from event sources. Subscription requests contain an event delivery mode and event filter mechanism to negotiate an event source with an event sink. Subscription Managers are responsible of holding subscriptions of event sources. |
WS-Eventing
WS-Eventing defines a protocol for managing subscriptions for a Web services based eventing mechanism. This protocol defines three endpoints: subscriber, event source and subscription manager. Subscribers request subscriptions on behalf of event sinks to receive events from event sources. Subscription requests contain an event delivery mode and event filter mechanism to negotiate event delivery mechanisms and event filter mechanism. Subscription managers are responsible of holding subscriptions of event sources. |
Ohne Hinweis auf eine Übernahme. |
|
| [12.] Saa/Fragment 015 01 - Diskussion Bearbeitet: 16. May 2015, 20:32 Hindemith Erstellt: 3. January 2015, 18:42 (Graf Isolan) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung, Zeeb et al 2007 |
|
|
|
| Untersuchte Arbeit: Seite: 15, Zeilen: 1-17 |
Quelle: Zeeb et al 2007 Seite(n): III-2 (Internetversion), Zeilen: li.Sp. 13-22, 41-48, 51-52, 54-57 |
|---|---|
| WS-Discovery
The WS-Discovery is a discovery protocol based on IP multicast for enabling services to be discovered automatically. Discovery introduces three different endpoint types: target service, client and discovery proxy. Target Services are Web Services offering themselves to the network, Clients may search for target services and discover them dynamically and Discovery Proxy is an endpoint enabling discovery in spanned networks since simple discovery is limited to a multicast group and hence to local managed networks only. WS-MetadataExchange / WS-Transfer WS-MetadataExchange is a specification that defines data types and operations to retrieve metadata associated with an endpoint. This metadata describes what other endpoints need to know to interact with the described endpoint, and defines the MetadataSection that divides the metadata into separate units of metadata with a dialect specifying its type. WS-Transfer is used to retrieve the metadata, which is structured as specifified in WS-MetadataExchange. MetadataExchange. There is a slight functional difference in WSMetadataExchange and WS-Transfer for retrieval of metadata. WS-MetadataExchange defines operations to retrieve all or parts of the metadata of an endpoint. WS-Transfer only can be used to retrieve all metadata of an endpoint. |
WS-Discovery
WS-Discovery is a discovery protocol based on IP multicast for enabling services to be discovered automatically. Discovery introduces three different endpoint types: target service, client and discovery proxy. Target services are Web services offering themselves to the network. Clients may search for target services and discover them dynamically. Discovery proxy is an endpoint enabling discovery in spanned networks since simple discovery is limited to a multicast group and hence to local managed networks only. [...] WS-MetadataExchange / WS-Transfer WS-MetadataExchange is a specification that defines data types and operations to retrieve metadata associated with an endpoint. This metadata describes what other endpoints need to know to interact with the described endpoint. WS-MetadataExchange defines the MetadataSection that divides the metadata into separate units of metadata with a dialect specifying its type. Until the latest version of DPWS only WS-MetadataExchange was used for service and device description and retrieval. In the latest DPWS version of February 2006 WS-Transfer is used to retrieve the metadata. The structure of the metadata is still as specified in WS-MetadataExchange. The main difference is that WS-MetadataExchange defined operations to retrieve all or parts of the metadata of an endpoint, whereas WS-Transfer only can be used to retrieve all metadata of an endpoint. |
Ohne Hinweis auf eine Übernahme. |
|
| [13.] Saa/Fragment 032 01 - Diskussion Bearbeitet: 16. May 2015, 20:15 Hindemith Erstellt: 1. January 2015, 22:48 (WiseWoman) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung, Wikipedia Electronic Data Interchange 2006 |
|
|
| Untersuchte Arbeit: Seite: 32, Zeilen: 1-21 |
Quelle: Wikipedia Electronic Data Interchange 2006 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| 2.6.7 EDI
EDI (Electronic Data Interchange) is the computer-to-computer exchange of structured information, by agreed message standards, from one computer application to another by electronic means and with a minimum of human intervention. In common usage, EDI is understood to mean specific interchange methods agreed upon by national or international standards bodies for the transfer of business transaction data, with one typical application being the automated registration of a patient in a hospital. Despite being relatively unheralded, in this era of technologies such as XML Web Services, the Internet and the WWW, EDI is still the data format used by the vast majority of electronic commerce transactions in the present computing world. The EDI standards were designed from the beginning to be independent of lower level technologies and can be transmitted using Internet protocols as well as private networks. It is important to differentiate between the EDI documents and the methods for transmitting them. There are two major sets of EDI standards. The first one is UN/EDIFACT, which is the only international standard (in fact, a United Nations recommendation) and is predominant in all areas outside of North America. The second is ANSI ASC X12 (X12), which is popular in North America and used worldwide. These standards prescribe the formats, character sets, and data elements used in the exchange of documents and forms, such as purchase orders (called ORDERS in UN/EDIFACT and an 850 in X12) and invoices. These standards say which pieces of information are mandatory for a particular document, which pieces are optional and give the rules for the structure of the document. |
Electronic Data Interchange (EDI) is the computer-to-computer exchange of structured information, by agreed message standards, from one computer application to another by electronic means and with a minimum of human intervention. In common usage, EDI is understood to mean specific interchange methods agreed upon by national or international standards bodies for the transfer of business transaction data, with one typical application being the automated purchase of goods and services.
Despite being relatively unheralded, in this era of technologies such as XML services, the Internet and the World Wide Web, EDI is still the data format used by the vast majority of electronic commerce transactions in the world. The EDI (Electronic Data Interchange) standards were designed from the beginning to be independent of lower level technologies and can be transmitted using Internet protocols as well as private networks. It is important to differentiate between the EDI documents and the methods for transmitting them. [...] [...] There are two major sets of EDI standards. UN/EDIFACT is the only international standard (in fact, a United Nations recommendation) and is predominant in all areas outside of North America. ANSI ASC X12 (X12) is popular in North America and used worldwide. These standards prescribe the formats, character sets, and data elements used in the exchange of documents and forms, such as purchase orders (called "ORDERS" in UN/EDIFACT and an "850" in X12) and invoices. The standard says which pieces of information are mandatory for a particular document, which pieces are optional and give the rules for the structure of the document. |
Ein Verweis auf die Quelle fehlt. |
|
| [14.] Saa/Fragment 043 01 - Diskussion Bearbeitet: 16. May 2015, 20:10 Hindemith Erstellt: 9. September 2014, 08:31 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 43, Zeilen: 1-2 |
Quelle: Vazquez 2007 Seite(n): 29, Zeilen: 1 ff. |
|---|---|
| Table 3.1 enumerates the criteria with relative weights depending on their importance to our goals.
Table 3.1: Criteria's relative weights of importance
|
Table 2.1 enumerates the criteria with relative weights depending on their importance to our goals.
Table 2.1: Criteria’s relative weights of importance. |

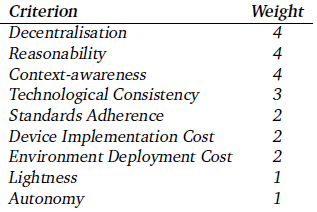
Ein Verweis auf die Quelle fehlt. Dies ist das Ende einer längeren Übernahme von der Vorseite: Fragment 042 01. |
|
| [15.] Saa/Fragment 042 01 - Diskussion Bearbeitet: 16. May 2015, 20:10 Hindemith Erstellt: 9. September 2014, 08:16 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 42, Zeilen: 1-8, 13-46 |
Quelle: Vazquez 2007 Seite(n): 25, 26, 27, 28, Zeilen: 25: 10 ff.; 26: 1 ff.; 27: 1 ff.; 28: 13 ff. |
|---|---|
| [- Lightness: The architectural elements and software components in particular should be designed in such a way that they could be easily embedded] in resource-constrained systems, i.e. medical or mobile devices, as well as promote operational simplicity if possible.
Technological - Standards Adherence: It represents the degree to which the envisaged system reuses and applies the widely accepted standards, thus taking advantage of previous R&D work and promoting re-usability in the industry and academia. The intention behind our research is to create new original work by assuring the highest possible degree of standards adherence. [...] - Technological Consistency: It represents the degree of coherence among the technologies used for the development of a system. The complementary technologies must be applied, if possible, in order to obtain synergistic performance and future re-usability. Intelligence - Reasoning Capability: It is the ability of the system to acquire and apply knowledge via reasoning (inferencing) process. In order to create the next generation of ambient intelligent medical or mobile devices, artificial intelligence techniques must be applied to a certain degree. - Context-Awareness: In simple terms, it is the ability of the system to perceive and identify the relevant information from an environment and actively respond according to the defined rules. Context-awareness is inevitably required to meet the ultimate goals of ubiquitous computing and ambient intelligent environments. The above-mentioned criteria are not completely isolated, rather certain dependencies exist among some of them in such a way that the degree of fulfillment in one concrete criterion can affect the other in a positive or negative manner. A high degree of decentralization favors the design of distributed lightweight components, instead of a bulky and heavy central controller. Lightweight components make the actual implementation feasible, but they also reduce the degree and quality of the embedded reasoning processes, which normally demand some amount of software complexity. The Reasoning Capability affects lightness negatively in the same way, since the more reasoning power the device is provided with, the heavier the component becomes. However, it promotes the context-awareness and autonomy, which can take advantage of the built-in intelligence to react accordingly. The Context-Awareness promotes autonomy, since architectural components can self-regulate their behavior depending on the context information provided by the surrounding entities. The Technological Consistency can significantly reinforce APIs reusability during the implementation, thus promoting more lightweight components that would be negatively affected by mixing up non-complementary technologies. At the same time, we consider that technological consistency simplifies the overall design by taking advantage of the existing mechanisms, procedures and interfaces. Not all these criteria are equally important, but depending on the desired strengths of the resulting architecture, some of them must be promoted. We will focus primarily on maximizing decentralization, reasoning capability, lightness and standards adherence, [and, in a lesser extent, technological consistency and context-awareness.] |
Lightness: architectural elements and software components in particular should be designed in such a way that they can be easily embeddable in resource-constrained platforms and devices, as well as promote operational simplicity if possible.
Intelligence Reasonability: is the ability of the system to acquire and apply knowledge via reasoning processes. In order to create the intelligence-enabling component of any smart device or environment, artificial intelligence techniques must be applied to a certain degree. Context-awareness: is the ability of the system to perceive and identify relevant information and perform reactive behaviour to provide the desired response. Intelligent context-awareness is the ultimate goal of Ubiquitous Computing and Ambient Intelligence. [...] Technological Technological consistency: represents the degree of coherence among the technologies used in a system. If possible, complementary technologies must be applied in order to obtain synergistic performance and future reusability. For example, transporting XML messages over HTTP is more natural, standardised and desirable than doing it over CORBA. [Seite 26] Standards adherence: represents the degree to which the designed system reuses and applies widely accepted standards, thus taking advantage of previous works and promoting skill reuse within the industry and academia. It is a major intention of our research to create new original work while assuring the highest possible degree of standards adherence. [...] These criteria are not isolated. Certain dependencies exist among some of them in such a way that the degree of fulfilment in one concrete criterion can affect other in a positive or negative manner. These dependencies are illustrated in Figure 2.1, where rows represent influencing criteria while columns represent influenced criteria. First, a high degree or decentralisation favours the design of distributed lightweight components, instead of a bulky and heavy central controller. Decentralisation also promotes a higher level of autonomy in architectural elements while reducing the scenario deployment cost, since environments are created by the emergent coordination of distributed elements. Lightweight components make feasible the actual implementation and promote a lower device implementation cost, but they also reduce the degree and quality of the embedded reasoning processes which normally demand some amount of software complexity. Reasonability affects lightness negatively in the same way, since the more reasoning power the device is provided with, the heavier the component becomes. In a similar way, hosting reasoning processes in constrained devices increases their costs and the efforts in terms of specialised workforce to implement these features. However, reasonability promotes both [Seite 27] context-awareness and autonomy, which can take advantage of the builtin intelligence to better determine the behaviour to perform. Context-awareness promotes autonomy, since architectural components can self-regulate their behaviour depending on context information provided by surrounding entities. The penalty for achieving a greater degree of awareness is, as usual, a higher device implementation cost. [...] Technological consistency can significantly reinforce APIs reusability during the implementation, thus promoting more lightweight components that would be negatively affected by mixing up non-complementary technologies. At the same time, we consider that technological consistency simplifies overall design by taking advantage of existing mechanisms, procedures and interfaces, thus reducing somehow the device implementation costs. [Seite 28] Not all these criteria are equally important, but depending on the desired strengths of the resulting architecture some of them must be promoted. We will focus primarily on maximising decentralisation, reasonability, contextawareness and, in a lesser extent, technological consistency. |
Ein Verweis auf die Quelle fehlt. In der untersuchten Arbeit findet man eine angepasste und gekürzte Version der entsprechenden Passage in der ungenannten Quelle. |
|
| [16.] Saa/Fragment 041 12 - Diskussion Bearbeitet: 16. May 2015, 20:10 Hindemith Erstellt: 9. September 2014, 07:59 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 41, Zeilen: 12-32 |
Quelle: Vazquez 2007 Seite(n): 24, 25, Zeilen: 24: 19 ff.; 25: 1 ff. |
|---|---|
| 3.1 Evaluation Criteria
In this section, we define a set of evaluation criteria by analyzing and evaluating state-of-the-art architectures, and determine how our proposal ranks in comparison with these architectures. Most of the selected criteria can be found, implicitly or explicitly, throughout all the literature concerning ubiquitous and pervasive computing architectures. The examples of these criteria are decentralization, context-awareness, autonomy and/or standards adherence, while other criteria are more specific to our research goals, i.e. having reasoning capability (inferencing) on medical devices, and communication with other medical or mobile devices through Web Services technology. In the following sections, we have organized the criteria into three different categories, namely Architectural, Technological and Intelligence, depending on their nature. Architectural - Decentralization: At the core of any ubiquitous computing system, decentralization endorses a spontaneous and unanticipated nature, non-critical components in the architecture, ad-hoc reconfiguration according to the situation, and natural deployment of elements and scalability. However, the design and planning of decentralized systems is more difficult, as well as resulting in a higher load of network traffic due to synchronization and coordination messages. - Lightness: The architectural elements and software components in particular should be designed in such a way that they could be easily embedded [in resource constrained systems, i.e. medical or mobile devices, as well as promote operational simplicity if possible.] |
2.1 Evaluation criteria
In order to analyse and evaluate the state-of-the-art architectures as well as to determine how our proposal ranks, we need to define a set of evaluation criteria. Most of the selected criteria can be found, implicitly or explicitly, throughout all the literature concerning ubiquitous and pervasive computing architectures: they represent core concepts and hot topics. Examples of these criteria are decentralisation, context-awareness, autonomy or standards adherence. Other criteria are more specific to our research goals such as reasonability or device implementation cost. However, the latter principles can also be easily found in similar related research. We have organised the criteria into four different categories depending on their nature: [Seite 25] Architectural Decentralisation: at the heart of any Ubiquitous Computing system, decentralisation promotes an spontaneous and serendipitous nature, non-critical components in the architecture, dynamic reconfiguration according to every situation, natural deployment of elements and scalability, among others. However, the design and planning of decentralised systems is more difficult, as well as resulting in a higher load of network traffic due to synchronisation and coordination messages. Lightness: architectural elements and software components in particular should be designed in such a way that they can be easily embeddable in resource-constrained platforms and devices, as well as promote operational simplicity if possible. |
Ein Verweis auf die Quelle fehlt. Der Text wurde z.T. angepasst, die Idee stammt jedoch erkennbar aus der ungenannten Quelle. |
|
| [17.] Saa/Fragment 097 01 - Diskussion Bearbeitet: 16. May 2015, 20:10 Hindemith Erstellt: 8. September 2014, 21:18 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 97, Zeilen: 1 ff. (komplett) |
Quelle: Vazquez 2007 Seite(n): 98, Zeilen: 1 ff. |
|---|---|
| Table 6.1: Comparison of SMDDP with State-of-the-art Discovery Protocols
|
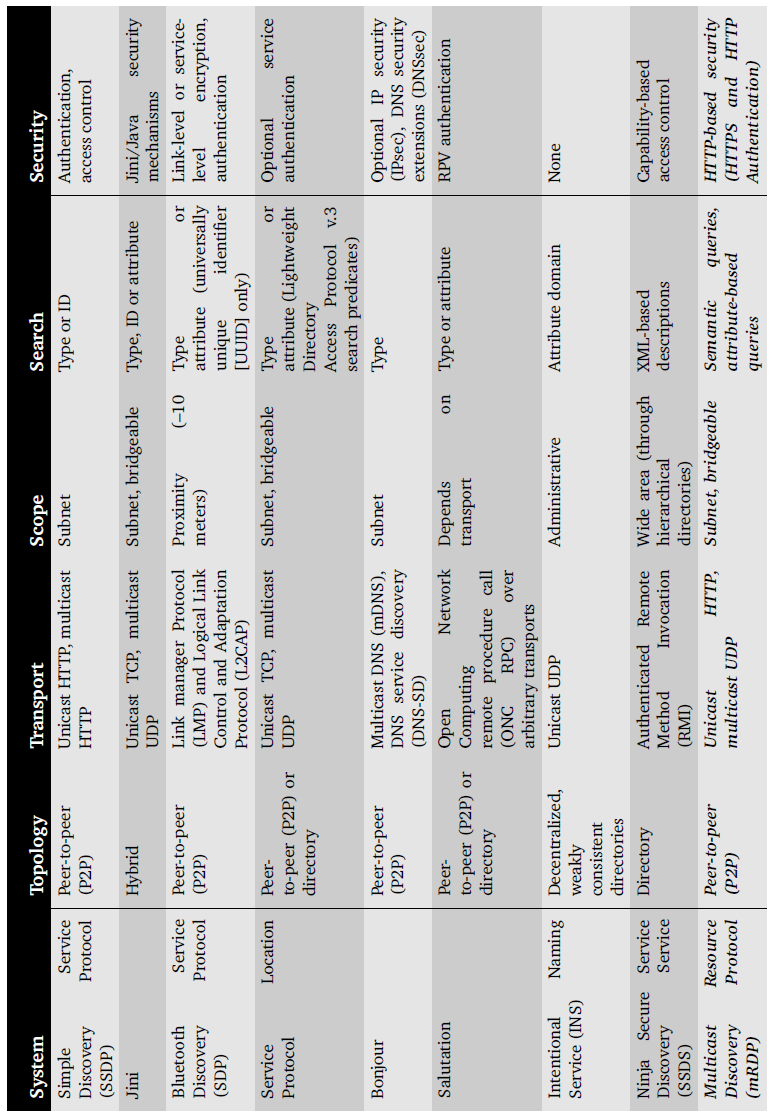
Table 3.1: Comparison of current discovery systems and mRDP. |
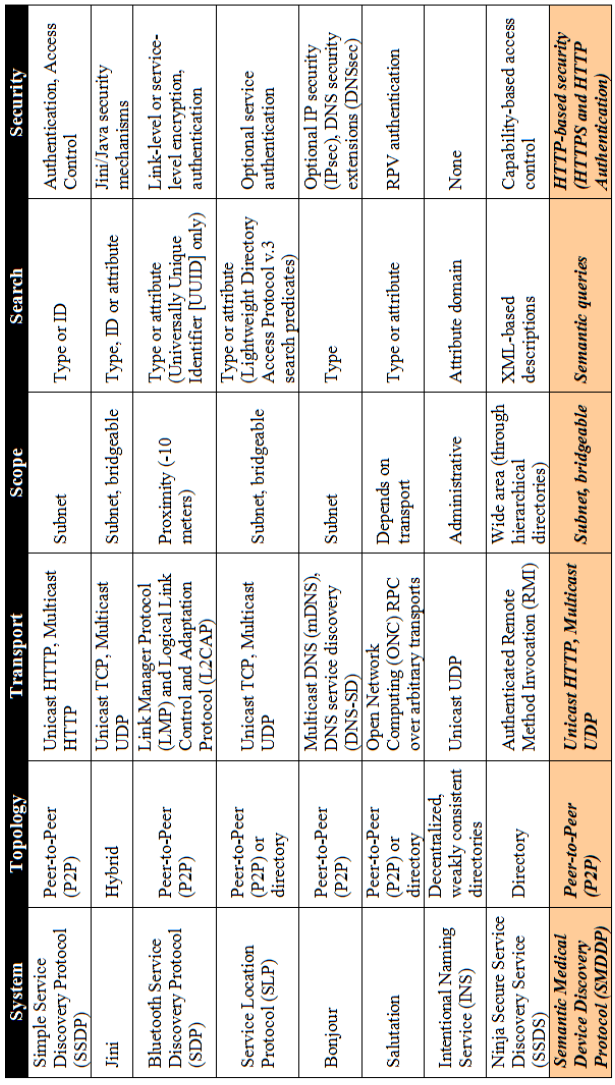
Ein Verweis auf die Quelle fehlt. Das Fragment ist im Zusammenhang mit Saa/Fragment 098 07 zu beurteilen. |
|
| [18.] Saa/Fragment 098 07 - Diskussion Bearbeitet: 16. May 2015, 20:09 Hindemith Erstellt: 8. September 2014, 21:13 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 98, Zeilen: 7-22 |
Quelle: Vazquez 2007 Seite(n): 96, 97, Zeilen: 96: 7 ff.; 97: 1 ff. |
|---|---|
| 6.5.2 Comparative Analysis
SMDDP provides a simple and powerful way for the semantic discovery of ambient intelligent medical devices in pervasive (healthcare) environments, utilizing and exploiting the advantages of HTTP protocol. Although, several discovery mechanisms for pervasive computing have been proposed in the past, but none of them is widely adopted. Edwards has published a comparative study [111] about SSDP, Jini, Bluetooth SDP, SLP, Bonjour, Salutation, INS and Ninja SSDS, including also infrared and RFID mechanisms. The comparison was based on different parameters, i.e. topology, transport, scope, search and security. Table 6.1 shows a reproduction of the Edwards' comparison table with the additional row of SMDDP, which exhibits some distinct factors by comparing it with other alternatives, such as its powerful semantic discovery capabilities and the use of widely-adopted and reliable HTTP-based security mechanisms. This comparison shows and promotes SMDDP to be the best candidate for the semantic discovery of ambient intelligent medical devices in pervasive computing scenarios within the healthcare domain, and also a valuable and promising alternative in other networking environments as well. [111] W. Keith Edwards, Discovery Systems in Ubiquitous Computing, IEEE Pervasive Computing, 5(2): 70-77, 2006. |
3.8 Comparative analysis
mRDP provides a simple and powerful way for performing semantic queries in Ubiquitous Computing environments, taking advantage and reusing HTTP infrastructure. Several discovery mechanisms for Ubiquitous Computing have been proposed in the past, none of them widely accepted. Edwards published a comparative [Edw06] about SSDP, Jini, Bluetooth SDP, SLP, Bonjour, Salutation, INS and Ninja SSDS, including also infrared and RFID mechanisms. The comparison was based on the criteria of topology, transport, scope, search and security. [Seite 97] We reproduce in Table 3.1 the comparison table with an additional row for mRDP5. mRDP exhibits some distinct factors from other alternatives, such as its powerful semantic search capabilities, and the use of well-proven and reliable HTTP-based security infrastructure. We deem mRDP to be the best candidate for intelligent discovery in pervasive computing scenarios, and also a valuable and promising alternative in other networking environments. 5 The rows for eSquirt (infrared) and RFID are not included, since they are not relevant for the current research. [Edw06] W. Keith Edwards. Discovery systems in ubiquitous computing. IEEE Pervasive Computing, 5(2):70–77, 2006. |
Ein Verweis auf die Quelle fehlt. |
|
| [19.] Saa/Fragment 056 01 - Diskussion Bearbeitet: 16. May 2015, 20:09 Hindemith Erstellt: 8. September 2014, 20:57 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 56, Zeilen: 1-24 |
Quelle: Vazquez 2007 Seite(n): 61, 62, Zeilen: 61: 6 ff.; 62: 11 ff. |
|---|---|
| Another strange mixture is related to the communication model, where Gaia uses CORBA as distributed computing architecture instead of the Web-based model.
The following sections provide analysis of Gaia against our defined evaluation criteria, and the conclusion is summarized in Table 3.5.
Table 3.5: Analysis of Gaia against the evaluation criteria
|
Another strange mixture is related to the communication model. Gaia uses CORBA as distributed computing architecture, instead of the web model. [...]
An analysis of Gaia against the evaluation criteria leads to the following results: Decentralisation: the requirement about a previous three-elements deployment in the environment contributes to a centralised architecture in Gaia. Low. Reasonability: the application of ontologies, rules, probabilistic logic, fuzzy logic and Bayesian networks in order to perform all sorts of reasoning about context information, promotes a very high degree of intelligence in Gaia. Very High. Context-awareness: the integration of rules and confidence values contribute to situation identification and subsequent adaptation. High. Technological Consistency: technological evolution during the Gaia project, resulting in changes as new technologies were adopted, has created a strange mixture in the final outcome. OWL is combined with predicate logics, instead of shifting to RDF. CORBA is applied as distributed computing architecture instead of newer more lightweight web-based communication models that would make the Semantic Web fit better. [...] Low. Standards Adherence: standards and recommendations such as CORBA and OWL are honoured. High. [Seite 62] Lightness: some elements in the architecture are difficult to migrate to resource-constrained devices, such as the Context History Service or the Ontology Server. The Gaia architecture does not seem to be intended for deployment in embedded devices, but in full computers. Low.
Table 2.5: Analysis of Gaia against the evaluation criteria. 2.6 Semantic |


Ein Verweis auf die Quelle fehlt. Auch die "analysis of Gaia against our defined evaluation criteria" stammt aus der Quelle. |
|
| [20.] Saa/Fragment 055 01 - Diskussion Bearbeitet: 16. May 2015, 20:09 Hindemith Erstellt: 8. September 2014, 20:46 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 55, Zeilen: 1 ff (komplett) |
Quelle: Vazquez 2007 Seite(n): 57, 58, 60, 61, Zeilen: 57: 28 ff.; 58: 1 ff.; 60: 14 ff.; 61: 1 ff. |
|---|---|

Figure 3.6: The Context Infrastructure in Gaia • Context Consumers: They gather context information from providers and synthesizers, reason about it and perform reactive behavior accordingly. • Context Provider Lookup Service: It is used by the context providers, one per environment, in order to publish the kind of context information they provide in order to be found by context consumers. • Context History Service: It contains database records, one per environment, of the past context information to make them available to the requesting parties. • Ontology Server: It stores ontologies, one per environment, for different types of information. 3.5.2 Conclusion Gaia fulfills many of the requirements established for a smart Ubiquitous Computing architecture, mainly those related to intelligence support. It makes use of context predicates for representing context information and OWL ontologies for taxonomical purposes. However, Gaia has two important drawbacks and several inconsistencies. The first main drawback is that, as a requisite, three different elements in the architecture must be deployed and properly configured in the environment: the Context Provider Lookup Service, the Context History Service and the Ontology Server. This constraint prevents Gaia from creating spontaneous emergent pervasive computing environments anywhere, since a deployment phase must me performed beforehand, enforcing an undesirable centralization. The second main disadvantage arises from the fact that core elements in the architecture, such as those three mentioned above, seem to be suitable for installation in desktop computers or servers, but not in embedded computers. The main inconsistencies with Gaia are originated from the initial selection of technologies and the subsequent integration of newer ones, that result in a strange mixture. For instance, representation of context information through predicates was present at the very initial stages, but when OWL ontologies were integrated in Gaia, context predicates remained as knowledge representation mechanisms instead of shifting to RDF, which [could have sound more sensible.] |
• Context Consumers: they gather context information from providers and synthesisers, reason about it and perform reactive behaviour accordingly.
• Context Provider Lookup Service: one per environment, it is used by context providers to publish the kind of context information they provide in order to be found by context consumers. • Context History Service: one per environment, it contains database records of past context information to make them available to requesting parties. [Seite 58] • Ontology Server: one per environment, stores ontologies for the different information types.
Figure 2.15: Gaia Context Infrastructure. Source: [RAMC04]. [Seite 60] 2.5.3 Conclusion Gaia fulfils many of the requirements established for a smart Ubiquitous Computing architecture, mainly those related to intelligence support. Gaia makes use of context predicates for representing context information and OWL ontologies for taxonomical purposes. [...] However, Gaia has two important drawbacks and several inconsistencies. The first main drawback is that Gaia requires three different elements in the architecture to be previously deployed and properly configured in the environment: the Context Provider Lookup Service, the Context History Service and the Ontology Server. This constraint prevents Gaia from creating spontaneous emergent pervasive computing environments anywhere, since a deployment phase must me performed beforehand, enforcing an undesirable centralisation. The second main disadvantage arises from the fact that core elements in the architecture, such as those three mentioned above, seem to be suitable for installation in desktop computers or servers, but not in embedded computers. [...] The main inconsistencies with Gaia are originated from the initial selection of technologies and the subsequent integration of newer ones, that result in a strange mixture. [Seite 61] For instance, representation of context information through predicates was present at the very initial stages. When OWL ontologies were integrated in Gaia, context predicates remained as knowledge representation mechanisms instead of shifting to RDF, which would have sound more sensible. [...] |

Ein Verweis auf die Quelle fehlt. |
|
| [21.] Saa/Fragment 054 01 - Diskussion Bearbeitet: 16. May 2015, 20:02 Hindemith Erstellt: 8. September 2014, 20:33 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 54, Zeilen: 1 ff. (komplett) |
Quelle: Vazquez 2007 Seite(n): 56, 57, Zeilen: 56: 17 ff.; 57: 1 ff. |
|---|---|

Figure 3.5: General Architecture of Gaia The mapping mechanism of the Application Framework offers the possibility of describing requirements to find the suitable real device to assign a functional behavior (for example, audio output) so that matching devices can be found within the active space to perform that function during a task. The interesting part is how Gaia represented context in the form of a 4-components structure: Context(<ContextType>, <Subject>, <Relater>, <Object>) that in many ways resembles that of the Semantic Web, for example: Context(locatedIn; CoaguChekS; is; RoomLab123). Later, this model evolved into a predicate-based representation of context information:
During 2003, Gaia was extended with a semantic middleware layer for context awareness endorsing existing Semantic Web technologies in order to model and annotate context information, perform reasoning and carry out reactive behavior in response to context changes [84]. DAML+OIL (later OWL) was selected to represent the context information following a predicate model. In order to map the predicates onto the ontology, an ontology class is created for each predicate structure. So, the above-mentioned Location predicate becomes a Location ontology class with three possible relationships to denote the information that was previously enclosed in the predicate parameters. Representing the context in this way, operations such as search, querying, fusion and so forth, become possible. There are several different entities involved in Gaia's context information infrastructure, as depicted in Fig. 3.6.
[84] Anand Ranganathan and Roy H. Campbell; A middleware for context-aware agents in ubiquitous computing environments; In Proceedings of the ACM/IFIP/USENIX International Middleware Conference, 2003. |
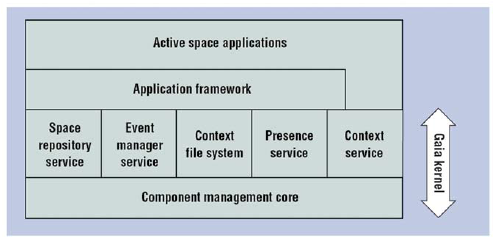
Figure 2.14: Gaia architecture. Source: [RHC+02b]. The mapping mechanism of the Application framework offers the possibility of describing requirements to find the suitable real device to assign a functional behaviour (for example, audio output) so that matching devices can be found within the active space to perform that function during a task. Specially interesting is how Gaia represented context in the form of a 4-components structure: Context(<ContextType>, <Subject>, <Relater>, <Object>) that in many ways resembles that of the Semantic Web, for example: Context(temperature, roomlab21, is, 24 C) . [Seite 57] Later, this model evolved into a predicate-based representation of context information: • Location(inaki, entering, roomlab21) • Temperature(roomlab21, ‘‘=’’, 24 C) • TVStatus(smallTV, is, off) During 2003, Gaia was extended with a semantic middleware layer for context awareness endorsing existing Semantic Web technologies in order to model and annotate context information, perform reasoning and carry out reactive behaviour in response to context changes [RC03b]. DAML+OIL (later OWL) was selected to represent the context information following a predicate model [MRCM03b] [MRMC03]. In order to map the predicates onto the ontology, an ontology class is created for each predicate structure [RC03a]. So, the Location predicate becomes a Location ontology class with three possible relationships to denote the information that was previously enclosed in the predicate parameters [MRCM03b]. Representing the context in this way, operations such as search, querying, fusion and so forth, become possible. There are several different entities involved in Gaia’s context information infrastructure depicted in Figure 2.15: • Context Providers: they are sources of context information, probably obtained by sensors. • Context Synthesisers: they retrieve context information from different providers and perform some form of reasoning to elicit new information making it available to other agents. Both static rules and machine learning techniques (such as Naïve Bayes) can be applied to obtain new information. [MRCM03b] Robert E. McGrath, Anand Ranganathan, Roy H. Campbell, and M. Dennis Mickunas. Use of ontologies in pervasive computing environments. Technical Report Technical Report UIUCDCS-R-2003-2332, University of Illinois at Urbana-Champaign, April 2003. [MRMC03] Robert E. McGrath, Anand Ranganathan, M. Dennis Mickunas, and Roy H. Campbell. Investigations of semantic interoperability in ubiquitous computing environments. In Proceedings of the 15th International Conference Parallel and Distributed Computing and Systems (PDCS), 2003. [RC03a] Anand Ranganathan and Roy H. Campbell. An infrastructure for context-awareness based on first order logic. Personal and Ubiquitous Computing, 7(6):353–364, 2003. [RC03b] Anand Ranganathan and Roy H. Campbell. A middleware for context-aware agents in ubiquitous computing environments. In Proceedings of the ACM/IFIP/USENIX International Middleware Conference, 2003. [RHC+02b] Manuel Román, Christopher Hess, Renato Cerqueira, Anand Ranganathan, Roy H. Campbell, and Klara Nahrstedt. A middleware infrastructure for active spaces. IEEE Pervasive Computing, 1(4):74–83, 2002. |
Ein Verweis auf die Quelle fehlt. |
|
| [22.] Saa/Fragment 053 01 - Diskussion Bearbeitet: 16. May 2015, 20:02 Hindemith Erstellt: 8. September 2014, 18:44 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 53, Zeilen: 1 ff. (komplett) |
Quelle: Vazquez 2007 Seite(n): 46, 54, 55, Zeilen: 46: Tabelle; 54: letzter Abschnitt; 55: 1 ff. |
|---|---|
| Table 3.4: Analysis of Task Computing against the evaluation criteria
3.5 Gaia Since 2001, the research group at the Department of Computer Science of the University of Illinois at Urbana-Champaign, led by Dr. Roy H. Campbell has been working on the design of an infrastructure to support intelligent Ubiquitous Computing environments. The Gaia project is the result of these efforts, constituting a software infrastructure to support Active Spaces. An active space is a "model that maps the abstract perception of a physical space as a computing system, into a first class software entity" [82]. Thus, the active space acts as a mapping between the real and virtual space, connecting both in such a way that real world actions affect virtual world objects and vice versa. The active space hides the complexity of the real world elements into one unique entity that provides functions for manipulating the space, discovering and locating internal entities, storing and retrieving information from the space and so forth. The name Gaia was adopted from the Gaia theory by James Lovelock that advocated for the earth as a self-regulated super-organism, who in turn borrowed it from the Greek Earth Goddess. The Gaia project tried to replicate the same global awareness and self-regulated behavior for smart environments and their constituent elements. 3.5.1 Gaia Architecture The Gaia Operating System (Gaia OS) is the core element of the whole architecture, which is defined as a meta-operating system, running at the top of others and providing a distributed communication model for coordinating active spaces [83]. Gaia is composed of three main components, as shown in Fig. 3.5.
[82] Manuel Román and Roy H. Campbell; Gaia: Enabling Active Spaces, In Proceedings of the 9th workshop on ACM SIGOPS European workshop, pages 229-234, New York, NY, USA, 2000. [83] Manuel Román, Christopher Hess, Renato Cerqueira, Anand Ranganathan, Roy H. Campbell, and Klara Nahrstedt; A middleware infrastructure for active spaces; IEEE Pervasive Computing, 1(4): 74-83, 2002. |
[Seite 46]
Table 2.3: Analysis of Task Computing against the evaluation criteria. [Seite 54] 2.5 Gaia Since 2001, the research group at the Department of Computer Science of the University of Illinois at Urbana-Champaign, led by Dr. Roy H. Campbell [Seite 55] has been working on the design of an infrastructure to support intelligent Ubiquitous Computing environments. The Gaia project is the result of these efforts, constituting a software infrastructure to support Active Spaces. An active space is a “model that maps the abstract perception of a physical space as a computing system, into a first class software entity” [RC00]. Thus, the active space acts as a mapping between the real and virtual space, connecting both in such a way that real world actions affect virtual world objects and vice versa. The active space hides the complexity of the real world elements into one unique entity that provides functions for manipulating the space, discovering and locating internal entities, storing and retrieving information from the space and so forth. [...] The name Gaia was adopted from the Gaia theory by James Lovelock that advocated for the earth as a self-regulated superorganism, who in turn borrowed it from the Greek Earth Goddess. The Gaia project tried to replicate the same global awareness and self-regulated behaviour for smart environments and their constituent elements. 2.5.1 Gaia architecture The Gaia Operating System (Gaia OS) is the core element of the whole architecture. It is defined as a meta-operating system, running at the top of others, providing a distributed communication model for coordinating active spaces [RHC+02b]. [Seite 55] Gaia is composed of three main components as shown in Figure 2.14: • Gaia kernel: provides basic services such as component life-cycle management or remote component execution and management. Gaia relies on CORBA as underlying distributed component model, and extends some CORBA services to provide the so-called Gaia services, such as Event service, Context service, Presence Service, Space repository and Context file system. • Application framework: consists of a distributed component-based infrastructure following the MVC model, including new functionality to manipulate component bindings, a mapping mechanism and policies/rules for application customisation. • Active Space Applications: implement the desired functional behaviour in the active space, such as the Presentation manager application, that lets users present slides in multiple displays simultaneously, move slides from one display to another, as well as move the input device functionality. [RC00] Manuel Rom´an and Roy H. Campbell. Gaia: enabling active spaces. In Proceedings of the 9th workshop on ACM SIGOPS European workshop, pages 229–234, New York, NY, USA, 2000. ACM Press. [RHC+02b] Manuel Rom´an, Christopher Hess, Renato Cerqueira, Anand Ranganathan, Roy H. Campbell, and Klara Nahrstedt. A middleware infrastructure for active spaces. IEEE Pervasive Computing, 1(4):74–83, 2002. |

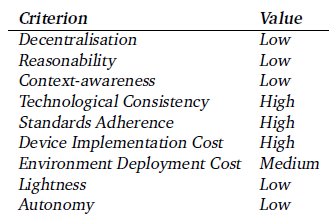
Ein Verweis auf die Quelle fehlt. |
|
| [23.] Saa/Fragment 052 01 - Diskussion Bearbeitet: 16. May 2015, 20:02 Hindemith Erstellt: 8. September 2014, 18:29 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 52, Zeilen: 1 ff. (komplett) |
Quelle: Vazquez 2007 Seite(n): 40, 43-45, Zeilen: 40: 8 ff.; 43: 7 ff.; 44: 1 ff.; 45: 1 ff. |
|---|---|
| A client implementing the Presentation Layer is usually referred to as Task Computing Client (TCC) and makes use of well-defined interfaces to the Middleware Layer.
Task Computing is implemented in concrete Task Computing Environments (TCEs), which are computational systems able to perform Task Computing functionality and composed of Task Computing Clients, Semantic Service Descriptions, Semantic Service Discovery Mechanisms and Service Controls. The detailed information about all of these components is given in the afore-mentioned literature. 3.4.2 Conclusion Task Computing is primarily a framework for services orchestration, composition, and execution. All the mechanisms it features are aimed at service publishing and discovery, semantic descriptions, service-ization of resources to make them available to any requester, and so forth. These features can be implemented in multiple environments, not being specially addressed for Ubiquitous Computing scenarios. In fact, Task Computing applies well-known Internet-wide technologies such as UDDI for discovery or traditional Web Services at external servers as endpoints. In order to assume a more context-aware nature, Task Computing has embraced some pervasive computing technologies to complement existing ones, such as UPnP's Simple Service Discovery Protocol (SSDP) for discovery, so services can be found both at a global level via UDDI and at a local level via the group by subnet discovery range. The following sections provide analysis of Task Computing technology against our defined evaluation criteria, and the conclusion is summarized in Table 3.4.
|
A client implementing the Presentation layer is usually referred to as Task Computing Client (TCC) and makes use of well-defined interfaces to the Middleware layer.
Task Computing is implemented in concrete TCEs (Task Computing Environments), which are computational systems able to perform Task Computing functionality and composed of Task Computing Clients, Semantic Service Descriptions, Semantic Service Discovery Mechanisms and Service Controls. [Seite 43] 2.3.3 Conclusion Task Computing is primarily a framework for services orchestration, composition, and execution. All the mechanisms it features are aimed at this goal: service publishing and discovery, semantic descriptions, service-ization of resources to make them available to any requester, and so forth. These features can be implemented in multiple environments, not being specially addressed for Ubiquitous Computing scenarios. In fact, Task Computing [Seite 44] applies well-known Internet-wide technologies such as UDDI for discovery or traditional Web Services at external servers as endpoints. In order to assume a more context-aware nature, Task Computing has embraced some pervasive computing technologies to complement existing ones, such as SSDP for discovery, so services can be found both at a global level via UDDI and at a local level via the group by subnet discovery range. [...] [...] An analysis of Task Computing against the evaluation criteria leads to the following results: Decentralisation: Task Computing is not aimed at creating a network of interconnected devices. The TCEs are intended to run in desktop computers or servers that can be connected to UPnP or Jini networks if device control is required. Low. Reasonability: Task Computing uses semantic information to annotate service descriptions and perform service composition, but neither reasoning nor domain ontologies are provided to understand context information. TC only is aimed at matching required and offered services. Low. [Seite 45] Context-awareness: except for service discovery mechanisms (which strictly is a technical issue, not related to context-awareness), no other form of capturing context, sensing environmental conditions, and so forth, are provided directly by Task Computing. No form of automatic responsive behaviour is provided in the model, but user intervention is required. Low. Technological Consistency: Task Computing applies web services and Semantic Web technologies in a coherent and synergistic manner. High. Standards Adherence: in general terms, Task Computing honours standards and recommendations trying to reuse existing technologies. Standards such as OWL-S, WSDL, HTTP, UDDI, and even industry de facto standards such as SSDP are widely used. High. [...] Lightness: processes such as Semantic-ization and Service-ization as well as the need of the Task Computing Client, result in complex and heavy software components. Devices need an amount of computing resources (processing power and screen size, among others) not presently available in every embedded platform. Low. |
Ein Verweis auf die Quelle fehlt. Auch die "analysis of Task Computing technology against our defined evaluation criteria" ist identisch zur Quelle |
|
| [24.] Saa/Fragment 051 01 - Diskussion Bearbeitet: 16. May 2015, 20:02 Hindemith Erstellt: 8. September 2014, 16:52 (Hindemith) | Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007 |
|
|
|
| Untersuchte Arbeit: Seite: 51, Zeilen: 1 ff. (komplett) |
Quelle: Vazquez 2007 Seite(n): 39, 40, Zeilen: 39: 25 ff.; 40: 1 ff. |
|---|---|

Figure 3.4: General Architecture of Task Computing Environment 3.4.1 Task Computing Architecture Fig. 3.4 shows the TC architecture [81], which is composed of four different layers, performing complementary activities:
[81] Zhexuan Song, Yannis Labrou, and Ryusuke Masuoka; Dynamic service discovery and management in Task Computing. In First Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services (MobiQuitous'04), pages 310-318, 2004. |
2.3.1 Task Computing architecture
The Task Computing architecture is composed of four different layers, performing complementary activities:
[Seite 40]
Figure 2.8: Task Computing architecture. Source: [SLM04]. service publishing. In some way, it glues services created at the Service layer with available underlaying technologies to support transport and management functions over them.
[SLM04] Zhexuan Song, Yannis Labrou, and Ryusuke Masuoka. Dynamic service discovery and management in task computing. In First Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services (MobiQuitous’04), pages 310–318, 2004. |
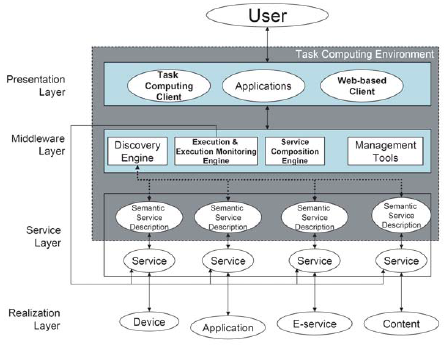
Ein Verweis auf die Quelle fehlt. |
|
| [25.] Saa/Fragment 050 03 - Diskussion Bearbeitet: 16. May 2015, 20:02 Hindemith Erstellt: 8. September 2014, 16:08 (Hindemith) | Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop, Vazquez 2007 |
|
|
|
| Untersuchte Arbeit: Seite: 50, Zeilen: 3-30 |
Quelle: Vazquez 2007 Seite(n): 38, 39, Zeilen: 38: 4 ff.; 39: 1ff. |
|---|---|
| 3.4 Task Computing
Task Computing3 (TC) technology is a joint effort by Fujitsu Laboratories of America and the MINDSWAP group, devoted to Semantic Web research, at the University of Maryland Institute for Advanced Computer Studies. The goal of TC is to "fill the gap between the tasks that users want to perform and the services that constitute available actionable functionality" [76]. TC presumes initially that users do not know how to achieve their goals when using computing facilities due to increased complexity at computing environments and tasks, and tries to ease the process by providing the user with an intelligent aid that hides the complexity of coordinating existing devices and services. TC provides dynamic service discovery, service publishing and management, task creation and execution on the fly [77]. It even assists users in discovering what their goals are by suggesting possible tasks that can be performed with available facilities. All these features try to solve the frustration of users in application-rich environments, where they have to orchestrate a variety of devices and applications. Using Task Computing they can focus on their final goal and accomplish it with a reduced number of simple interactions. Service composition can be seen as the "process of creating customized services from existing services by a process of dynamic discovery, integration and execution of those services in a planned order to satisfy a request from a client" [78]. Some examples of documented scenarios [79] that can be accomplished using TC technology are: exchanging business cards, showing and sharing a presentation, scheduling a future presentation or checking and printing directions to the airport. All of them are accomplished by sharing services on different devices and orchestrating those services to create a work flow in order to carry out the desired task. A prototype of TC has been implemented experimentally for Smart Conference Rooms and Home Multimedia Environments [80] and the first public results date back to 2003. It consisted in applying Semantic Web technologies to Pervasive Computing scenarios for semi-automatic composition of tasks, based on their previous research [77]. 3 Task Computing - the Technology; http://taskcomputing.org/ [76] Ryusuke Masuoka, Yannis Labrou, Bijan Parsia, and Evren Sirin; Ontology-enabled pervasive computing applications, IEEE Intelligent Systems, 18(5): 68-72, September- October 2003. [77] Evren Sirin, James Hendler, and Bijan Parsia. Semi-automatic composition of web services using semantic descriptions. In Web Services: Modeling, Architecture and Infrastructure workshop in ICEIS 2003, Angers, France, April 2003. [78] Dipanjan Chakraborty, Filip Perich, Anupam Joshi, Tim Finin, and Yelena Yesha; A reactive service composition architecture for pervasive computing environments, Technical report, University of Maryland, Baltimore County, March 2002. [79] Ryusuke Masuoka, Bijan Parsia, and Yannis Labrou; Task Computing - The Semantic Web meets Pervasive Computing. In Proceedings of 2nd International Semantic Web Conference (ISWC2003), Sanibel Island, Florida, October 2003. [80] Zhexuan Song, Ryusuke Masuoka, Jonathan Agre, and Yannis Labrou; Task Computing for ubiquitous multimedia services. In MUM'04: Proceedings of the 3rd international conference on Mobile and ubiquitous multimedia, pages 257-262, New York, USA, 2004. ACM Press. |
2.3 Task Computing
Task Computing is an ongoing joint effort by Fujitsu Laboratories of America and the MINDSWAP group, devoted to Semantic Web research, at the University of Maryland Institute for Advanced Computer Studies. The goal of Task Computing is to “fill the gap between the tasks that users want to perform and the services that constitute available actionable functionality” [MLPS03]. Task Computing presumes initially that users do not know how to achieve their goals when using computing facilities due to increased complexity at computing environments and tasks, and tries to ease the process by providing the user with an intelligent aid that hides the complexity of coordinating existing devices and services. Task Computing provides dynamic service discovery, service publishing and management, task creation and execution on the fly [SHP03]. It even assists users in discovering what their goals are by suggesting possible tasks that can be performed with available facilities. All these features try to solve the frustration of users in application-rich environments, where they have to orchestrate a variety of devices and applications. Using Task Computing they can focus on their final goal and accomplish it with a reduced number of simple interactions. Service composition can be seen as the “process of creating customized services from existing services by a process of dynamic discovery, integration [Seite 39] and execution of those services in a planned order to satisfy a request from a client” [CPJ+02]. Some examples of documented scenarios [MPL03] that can be accomplished using Task Computing technology are: exchanging business cards, showing and sharing a presentation, scheduling a future presentation or checking and printing directions to the airport. All of them are accomplished by sharing services on different devices and orchestrating those services to create a workflow in order to carry out the desired task. A prototype of Task Computing environment has been implemented experimentally for Smart Conference Rooms and Home Multimedia Environments [SMAL04] and the first public results date back to 2003, where the group of researchers led by Dr. Ryusuke Masuoka at Fujitsu Laboratories and Dr. James Hendler at the University of Maryland published several papers [MPL03, MLPS03, MMS+05] explaining the basics of their approach. It consisted in applying Semantic Web technologies to Pervasive Computing scenarios for semi-automatic composition of tasks, based on their previous research [SHP03]. [CPJ+02] Dipanjan Chakraborty, Filip Perich, Anupam Joshi, Tim Finin, and Yelena Yesha. A reactive service composition architecture for pervasive computing environments. Technical report, University of Maryland, Baltimore County, March 2002. [MLPS03] Ryusuke Masuoka, Yannis Labrou, Bijan Parsia, and Evren Sirin. Ontology-enabled pervasive computing applications. IEEE Intelligent Systems, 18(5):68–72, September-October 2003. [MMS+05] Ryusuke Masuoka, MohinderChopra, Zhexuan Song, Yannis Labrou, Lalana Kagal, and Tim Finin. Policy-based access control fortask computing using rei. In Proceedings of the Policy Management for theWeb Workshop, WWW2005, pages 37–43. W3C, May 2005. [MPL03] Ryusuke Masuoka, Bijan Parsia, and Yannis Labrou. Task computing - the semantic web meets pervasive computing. In Proceedings of 2nd International Semantic Web Conference (ISWC2003), Sanibel Island, Florida, October 2003. [SHP03] Evren Sirin, James Hendler, and Bijan Parsia. Semi-automatic composition of web services using semantic descriptions. In Web Services: Modeling, Architecture and Infrastructure workshop in ICEIS 2003, Angers, France, April 2003. [SMAL04] Zhexuan Song, Ryusuke Masuoka, Jonathan Agre, and Yannis Labrou. Task computing for ubiquitous multimedia services. In MUM ’04: Proceedings of the 3rd international conference on Mobile and ubiquitous multimedia, pages 257–262, New York, NY, USA, 2004. ACM Press. |
Ein Verweis auf die Quelle fehlt. |
|
| [26.] Saa/Fragment 057 16 - Diskussion Bearbeitet: 16. May 2015, 20:02 Hindemith Erstellt: 7. September 2014, 21:44 (Hindemith) | Fragment, Gesichtet, Klusch 2006, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 57, Zeilen: 16-47 |
Quelle: Klusch 2006 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| Mikka spends his summer vacations in Portugal. Unfortunately, after one week in Lisbon he becomes seriously ill, suffering from a disease unknown to him. In this emergency situation, he activates his personal Health-SCALLOPS agent on his PDA with an integrated phone for help, as shown in Fig. 3.7. The agent quickly finds and calls the nearest local emergency center in Portugal, and Mikka describes the observable symptoms of his disease. At the same time, his Health-SCALLOPS agent transfers general, non-sensitive information about Mikka and his current location to the patient database of the emergency center. The local representative at the Portuguese emergency center quickly recognizes that Mikka's symptoms are very serious and strongly recommends him to immediately visit the nearest hospital. Hospital contact information including geographical map and how to reach the ambulance station are transmitted to Mikka's PDA by the Health-SCALLOPS emergency center agent. Mikka readily arrives at the hospital's ambulance station by taxi, passes his individual health patient card (HPC) to the physician, and authorizes him to access his patient record. Mikka may decide whether he wants to get full treatment at the local hospital, or at a hospital of his choice back home in Helsinki. In order to make a reasonable decision, Mikka requests his personal Health-SCALLOPS agent on his PDA for appropriate assistance in this matter.
Given task and requirements, the agent contacts the Health-SCALLOPS agent of Mikka's health insurance (HI) for approval of full coverage of travel and medical expenses in both cases. The HI agent contracts the Health-SCALLOPS agent of an emergency medical assistance (EMA) company in Helsinki to investigate transport options and cost estimations with respect to the regulatory constraints of the insurance fund. For this purpose, the EMA agent plans a composite service to go home and have his treatment in Helsinki. Appropriate services in the network check the availability of regular or charter flights from Lisbon to Helsinki, accommodation and medical escort of Mikka to and from the airport, and the availability of a physician for Mikka's treatment at the hospital in Helsinki at the time of his arrival. Optional plans of patient transport and costs are reported back to the HI agent, which [sic] negotiates options for Mikka's treatment with the local hospital agent in Lisbon and pharmacy agents in the network for purchasing the required drugs for his treatment. All agents involved use the information of some individual experience while handling similar emergency cases in the past. The results of both kinds of negotiations enable the HI agent to make its decision through individually [composed health care expense approval service of Mikka's insurance fund according to his membership status.] |
Only one year later, Mikka spends his summer vacation in Portugal. Unfortunately, after one week in Lisbon he becomes seriously ill, suffering from a disease unknown to him. In this emergency situation, he activates his personal Health-SCALLOPS agent on his PDA with an integrated phone for help.
[...] The agent quickly finds and calls the nearest local emergency center in Portugal, and Mikka describes the observable symptoms of his disease. At the same time, his Health-SCALLOPS agent transfers general, non-sensitive information about Mikka and his current location to the patient database of the emergency center. The local representative at the Portuguese emergency center quickly recognizes that Mikka's symptoms are very serious and strongly recommends him to immediately visit the nearest hospital. Hospital contact information including geographical map and how to reach the ambulance station are transmitted to Mikka's PDA by the Health-SCALLOPS emergency center agent. In contrast to his state in Sweden last year (cf. Scenario 1), Mikka readily arrives at the hospital's ambulance station by taxi, passes his individual health patient card (HPC) to the physician, and authorizes him to access his patient record. Mikka may decide whether he wants to get full treatment at the local hospital, or at a hospital of his choice back home in Helsinki. In order to make a reasonable decision, Mikka requests his personal Health-SCALLOPS agent on his PDA for appropriate assistance in this matter. Coverage of Emergency Medical Care and Transport Given task and requirements, the agent contacts the Health-SCALLOPS agent of Mikka's health insurance (HI) for approval of full coverage of travel and medical expenses in both cases. The HI agent contracts the Health-SCALLOPS agent of an emergency medical assistance (EMA) company in Helsinki to investigate transport options and cost estimations with respect to the regulatory constraints of the insurance fund. For this purpose, the EMA agent plans a composite service to go home and have his treatment in Helsinki. Appropriate services in the network check the availability of regular or charter flights from Lisbon to Helsinki, accommodation and medical escort of Mikka to and from the airport, and the availability of a physician for Mikka's treatment at the hospital in Helsinki at the time of his arrival. Optional plans of patient transport and costs are reported back to the HI agent. Concurrently, the HI agent negotiates options for Mikka's treatment with the local hospital agent in Lisbon and pharmacy agents in the network for purchasing the required drugs for his treatment. All agents involved use the information of some individual experience while handling similar emergency cases in the past. The results of both kinds of negotiations enable the HI agent to make its decision through individually composed health care expense approval service of Mikka's insurance fund according to his membership status. |
Ein Verweis auf die Quelle fehlt. |
|
| [27.] Saa/Fragment 010 04 - Diskussion Bearbeitet: 16. May 2015, 20:02 Hindemith Erstellt: 7. September 2014, 12:07 (Hindemith) | Fragment, Gesichtet, Martin 2005, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 10, Zeilen: 4-32 |
Quelle: Martin_2005 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| Loosely Coupled
Unlike traditional application designs, which depend upon a tight interconnection of all program elements, Web Services are loosely coupled. Loose-coupling means that each service exists independently of the other services that make up the application. This allows individual pieces of the application to be modified without impacting unrelated areas. As a critical requirement for Service Oriented Architecture (SOA) design, loose-coupling is to be provided by Web Services through established standards that define services and how they interoperate. Enables Service-Oriented Architectures Web Services represent the convergence between the service-based development of applications and the Web. In the SOA model, the business processes that make up an application are separated into independent, easily distributed components known as services. These services interoperate across processes and machines to create a complete solution for a business problem. This loose-coupling allows for easy changes to the application by inserting new and revised services into the application without having modifying the unrelated services. Ease of Integration Unlike other methods of integration, Web Services are becoming widely adopted across the entire software industry. This broad industry adoption helps alleviate companies fears of proprietary technologies that may lock them in for the future. The standards surrounding Web Services are human-readable and publicly available, allowing a developer to view exactly what is happening in the system. Most often, integration between business partners is as easy as agreeing to a standard format for exchange of information defined in XML and WSDL. Easily Accessible Finally, Web Services are distributed over the Internet. Web Services make use of existing ubiquitous transport protocols like HTTP, leveraging existing infrastructure and allowing information to be requested and received in real time. Current IT infrastructure for addressing, security and performance can also be applied to Web Services applications. |
Some of the benefits to web services include:
“Loosely Coupled Unlike traditional application designs, which depend upon a tight interconnection of all program elements, Web services are loosely coupled. Loose coupling means that each service exists independently of the other services that make up the application. This allows individual pieces of the application to be modified without impacting unrelated areas. A critical requirement for SOA design, loose-coupling is ably provided by Web services through established standards that define services and how they interoperate. Enables Service-Oriented Architectures Web services represent the convergence between the service-based development of applications and the Web. In the SOA model, the business processes that make up an application are separated into independent, easily distributed components known as services. These processes interoperate across processes and machines to create a complete solution for a business problem. This loose coupling allows for easy changes to the application by inserting new and revised services into the application without having to modify the unrelated services. Ease of Integration Unlike other methods of integration, Web services are becoming widely adopted across the entire software industry. This broad industry adoption helps alleviate companies’ fears of proprietary technologies that may “lock” them in for the future. The standards surrounding Web services are human-readable and publicly available, allowing a developer to view exactly what is happening in the system. Most often, integration between business partners is as easy as agreeing to a standard format for exchange of information defined in XML and WSDL. [...] Easily Accessible Finally, Web services are distributed over the Internet. Web services make use of existing, ubiquitous transport protocols like HTTP, leveraging existing infrastructure and allowing information to be requested and received in real time. Current IT infrastructure for addressing, security and performance can be applied to Web services applications as well.”(RougeWave Software) RougeWave Software. “An Introduction to Web Services” 3 Apr. 2005 www.roguewave.com |
Ein Verweis auf die Quelle fehlt. Die hier dokumentierte Quelle zitiert die Passage wörtlich (und kennzeichnet dies deutlich). Möglicherweise findet sich die Passage auch noch in anderen Quellen. Vor der hier dokumentierten Passage wird angeführt: "In this section, we discuss the key benefits of the Web Services to enlighten the reasons of their wide adoption in the industry [32]. [32] ARMUS Corporation, Introduction to Web Services" Dazu sei angemerkt, dass |
|
| [28.] Saa/Fragment 019 01 - Diskussion Bearbeitet: 16. May 2015, 20:01 Hindemith Erstellt: 6. September 2014, 21:08 (Hindemith) | Cabral et al 2004, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 19, Zeilen: 1ff (komplett) |
Quelle: Cabral et al 2004 Seite(n): 231, 232, Zeilen: 231: 13 ff.; 232: 1 ff. |
|---|---|
| [In general, a broker would check that the preconditions] of tasks and services are satisfied and prove that the services post-conditions and effects imply goal accomplishment. An explanation of the decision making process should also be provided. The Composition or choreography allows SWS to be defined in terms of other simpler services. A workflow expressing the composition of atomic services can be defined in the service ontology by using appropriate control constructs. This description would be grounded on a syntactic description such as BEPL4WS [47]. Dynamic composition is also being considered as an approach during service request in which the atomic services required to solve a request are located and composed on the y. That requires an invoker which matches the outputs of atomic services against the input of the requested service.
The invocation of SWS involves a number of steps, once the required inputs have been provided by the service requester. First, the service and domain ontologies associated with the service must be instantiated. Second, the inputs must be validated against the ontology types. Finally the service can be invoked or a workflow executed through the grounding provided. It is also important to monitor the status of the decomposition process and notify the requester in case of exceptions. The deployment of a Web Service by a provider is independent of the publishing of its semantic descriptions since the same Web Service can serve multiple purposes. Also, the SWS infrastructure can provide a facility for the instant deployment of code for a given semantic description. The management of service ontologies is a cornerstone activity for SWS since it will guarantee that the semantic service descriptions are created, accessed and reused within the Semantic Web. Architecture From the architecture perspective, as shown in Fig. 2.4, SWSs are defined by a set of components which realize the activities above, with underlying security and trust mechanisms. The components gathered from the discussion above include: a register, a reasoner, a matchmaker, a decomposer and an invoker. The reasoner is used during all activities and provides the reasoning support for interpreting the semantic descriptions and queries. The register provides the mechanisms for publishing and locating services in a semantic registry as well as functionalities for creating and editing service descriptions. The matchmaker mediates between the requester and the register during the discovery and selection of services. The decomposer is the component required for executing the composition model of composed services. The invoker mediates between requester and provider or decomposer and provider when invoking services. These components are illustrative of the required roles in the SWS architecture for the discussion here as they can have different names and a complexity of their own in different approaches. Service Ontology The service ontology is another dimension under which we can define the SWS, for it represents the capabilities of a service itself and the restrictions applied to its use. The service ontology essentially integrates at the knowledge-level the information which has been defined by Web Services standards, such as UDDI and WSDL with related domain knowledge. This would include: functional capabilities such as inputs, output, pre-conditions and post-conditions; and non-functional capabilities such as category, cost and quality of service; provider related information, such as company name and address; task or goal-related information; and domain knowledge defining, for instance, the type of the inputs of the service. This information can, in fact be divided in several ontologies. However, the service ontology used for describing SWS will rely on the expressivity and inference power of the underlying ontology language supported by the Semantic Web. [47] BPEL4WS Consortium. Business Process Execution Language for Web Services; http://www.ibm.com/developerworks/ library/specification/ws-bpel/ |
In general, a broker would check that the preconditions of tasks and services are satisfied and prove that the services post-conditions and effects imply goal accomplishment. An explanation of the decision-making process should also be provided.
Composition or choreography allows SWS to be defined in terms of other simpler services. A workflow expressing the composition of atomic services can be defined in the service ontology by using appropriate control constructs. This description would be grounded on a syntactic description such as BEPL4WS [5]. Dynamic composition is also being considered as an approach during service request in which the atomic services required to solve a request are located and composed on the fly. That requires an invoker which matches the outputs of atomic services against the input of the requested service. The invocation of SWS involves a number of steps, once the required inputs have been provided by the service requester. First, the service and domain ontologies asso- [Seite 232] ciated with the service must be instantiated. Second, the inputs must be validated against the ontology types. Finally the service can be invoked or a workflow executed through the grounding provided. Monitoring the status of the decomposition process and notifying the requester in case of exceptions is also important. The deployment of a Web service by a provider is independent of the publishing of its semantic description since the same Web service can have serve multiple purposes. But, the SWS infrastructure can provide a facility for the instant deployment of code for a given semantic description. The management of service ontologies is a cornerstone activity for SWS since it will guarantee that semantic service descriptions are created, accessed and reused within the Semantic Web. From the architecture perspective (fig. 4), SWS are defined by a set of components which realize the activities above, with underlying security and trust mechanisms. The components gathered from the discussion above include: a register, a reasoner, a matchmaker, a decomposer and an invoker. The reasoner is used during all activities and provides the reasoning support for interpreting the semantic descriptions and queries. The register provides the mechanisms for publishing and locating services in a semantic registry as well as functionalities for creating and editing service descriptions. The matchmaker will mediate between the requester and the register during the discovery and selection of services. The decomposer is the component required for executing the composition model of composed services. The invoker will mediate between requester and provider or decomposer and provider when invoking services. These components are illustrative of the required roles in the SWS architecture for the discussion here as they can have different names and a complexity of their own in different approaches. The service ontology is another dimension under which we can define SWS (fig. 4), for it represents the capabilities of a service itself and the restrictions applied to its use. The service ontology essentially integrates at the knowledge-level the information which has been defined by Web services standards, such as UDDI and WSDL with related domain knowledge. This would include: functional capabilities such as inputs, output, pre-conditions and post-conditions; non-functional capabilities such as category, cost and quality of service; provider related information, such as company name and address; task or goal-related information; and domain knowledge defining, for instance, the type of the inputs of the service. This information can, in fact be divided in several ontologies. However, the service ontology used for describing SWS will rely on the expressivity and inference power of the underlying ontology language supported by the Semantic Web. 5. BPEL4WS Consortium. Business Process Execution Language for Web Services. http://www.ibm.com/developerworks/ library/ws-bpel |
Ein Verweis auf die Quelle fehlt. |
|
| [29.] Saa/Fragment 106 21 - Diskussion Bearbeitet: 16. May 2015, 20:01 Hindemith Erstellt: 6. September 2014, 14:10 (Hindemith) | BauernOpfer, Fragment, Gesichtet, Protegewiki 2008, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 106, Zeilen: 21-29 |
Quelle: Protegewiki 2008 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| Protégé19 is a free, open-source platform that provides a growing user community with a suite of tools to construct domain models and knowledge-based applications with ontologies. At its core, Protégé implements a rich set of knowledge-modeling structures and actions that support the creation, visualization, and manipulation of ontologies in various representation formats. The Protégé platform supports two main ways of modeling ontologies: the Protégé-Frames editor enables users to build and populate ontologies that are frame-based, in accordance with the OKBC (Open Knowledge Base Connectivity) protocol; while the Protégé-OWL editor enables users to build ontologies for the Semantic Web, in particular in the W3C's OWL (Web Ontology Language) language.
19 Protégé - An Ontology Editor and Knowledge base Framework; http://protege.stanford.edu/ |
Protege is a free, open-source platform that provides a growing user community with a suite of tools to construct domain models and knowledge-based applications with ontologies. At its core, Protege implements a rich set of knowledge-modeling structures and actions that support the creation, visualization, and manipulation of ontologies in various representation formats. [...]
[...] The Protege platform supports two main ways of modeling ontologies:
|
Eine Quelle für den Text ist in Fußnote 19 angegeben, dieser Text wird sehr oft verwendet, um dieses Werkzeug zu beschreiben. Trotz der Verbreitung des Texts wäre eine Kennzeichnung als wörtliches Zitat zu erwarten gewesen. |
|
| [30.] Saa/Fragment 018 01 - Diskussion Bearbeitet: 16. May 2015, 09:35 Hindemith Erstellt: 6. September 2014, 21:01 (Hindemith) | Cabral et al 2004, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 18, Zeilen: 1ff (komplett) |
Quelle: Cabral et al 2004 Seite(n): 6, 7, Zeilen: 6: 39ff; 7: 1ff |
|---|---|

Figure 2.4: Semantic Web Services Infrastructure Dimensions [The activities required for running an application using SWS] include: publishing, discovery, selection, composition, invocation, deployment and ontology management, as described next. The publishing or advertisement of SWS will allow agents or applications to discover services based on its goals and capabilities. A semantic registry is used for registering instances of the service ontology for individual services. The service ontology distinguishes between information which is used for matching during the discovery and that is used during service invocation. In addition, domain knowledge should also be published or linked to the service ontology. The discovery of services consists of a semantic matching between the description of a service request and the description of published service. The queries involving the service name, input, output, preconditions and other attributes can be constructed and used for searching the semantic registry. The matching can also be done at the level of tasks or goals to be achieved, followed by a selection of services which solves the task. The degree of matching can be based on some criteria, such as the inheritance relationship of types. For example, an input of type Infusion Pump of a provided service can be said to match an input of type Medical Device of a requested service. A selection of services is required if there is more than one service matching the request. Non-functional attributes such as cost or quality can be used for choosing one service. In a more specialized or agent-based type of interaction a negotiation process can be started between a requester and a provider, but that requires that the services themselves be knowledge-based. |
The activities required for running an application using SWS include: publishing, discovery, selection, composition, invocation, deployment and ontology management, as described next.
[Seite 7] The publishing or advertisement of SWS will allow agents or applications to discover services based on its goals and capabilities. A semantic registry is used for registering instances of the service ontology for individual services. The service ontology distinguishes between information which is used for matching during discovery and that used during service invocation. In addition, domain knowledge should also be published or linked to the service ontology. The discovery of services consists of a semantic matching between the description of a service request and the description of published service. Queries involving the service name, input, output, preconditions and other attributes can be constructed and used for searching the semantic registry. The matching can also be done at the level of tasks or goals to be achieved, followed by a selection of services which solves the task. The degree of matching can be based on some criteria, such as the inheritance relationship of types. For example, an input of type Professor of a provided service can be said to match an input of type Academic of a requested service.
Fig. 4. Semantic Web Services infrastructure dimensions. A selection of services is required if there is more than one service matching the request. Non-functional attributes such as cost or quality can be used for choosing one service. In a more specialized or agent-based type of interaction a negotiation process can be started between a requester and a provider, but that requires that the services themselves be knowledge-based. |

Ein Verweis auf die Quelle fehlt. Man beachte die Anpassung an die Thematik der untersuchten Arbeit: "Professor" --> "Infusion Pump" "Academic" --> "Medical Device" |
|
| [31.] Saa/Fragment 028 19 - Diskussion Bearbeitet: 1. January 2015, 23:43 WiseWoman Erstellt: 6. September 2014, 19:37 (Hindemith) | Benson 2004, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 28, Zeilen: 19-30 |
Quelle: Benson 2004 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| HL7 is like a language and every language has a grammar. The HL7 RIM specifies the grammar of HL7 messages and specifically the basic building blocks of the language and their permitted relationships. The RIM is neither a model of healthcare, though it is healthcare specific, nor is it a model of any message, though it is used in messages. At first site the RIM is quite simple, as the RIM backbone has just five core classes and a number of permitted relationships between them. In HL7 v.3.0, every event is an Act, which is analogous to a verb in English. Each Act may have any number of Participations, in Roles, played by Entities. These are analogous to nouns. Each Act may also be related to other Acts, via Act-Relationships. Act, Role and Entity classes also have a number of specializations, for example, Entity has a specialization called Living Subject, which itself has a specialization called Person. Person inherits the attributes of both Entity and Living Subject. | HL7 is a language, and every language has a grammar. The HL7 RIM (Reference Information Model) specifies the grammar of HL7 messages and, specifically, the basic building blocks of the language and their permitted relationships. The RIM is not a model of healthcare, although it is healthcare specific, nor is it a model of any message, although it is used in messages. At first site the RIM is quite simple. The RIM backbone has just five core classes and a number of permitted relationships between them.
In HL7, every happening is an Act, which is analogous to a verb in English. Each Act may have any number of Participations, in Roles, played by Entities. These are analogous to nouns. Each Act may also be related to other Acts, via Act-Relationships. Act, Role and Entity classes also have a number of specialisations. For example, Entity has a specialisation called Living Subject, which itself has a specialisation called Person. Person inherits the attributes of both Entity and Living Subject. |
Ein Verweis auf eine Quelle fehlt. Der Homonym-Fehler "At first site" (sollte "At first sight" sein) wird getreu übernommen, auf der HL7-Seite (http://www.hl7.com.au/V3-Resources.htm) wird der korrekte Begriff verwendet. |
|
| [32.] Saa/Fragment 032 23 - Diskussion Bearbeitet: 1. January 2015, 23:11 WiseWoman Erstellt: 6. September 2014, 08:25 (Hindemith) | BauernOpfer, Fragment, Gesichtet, IHE FAQ 2004, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 32, Zeilen: 23-35 |
Quelle: IHE FAQ 2004 Seite(n): 1, 3, Zeilen: 1: 3. Spalte: 24ff; 3: 1. Spalte: 3ff |
|---|---|
| Interfacing systems is one of the key challenges faced by IT staff of any healthcare institution. Understanding the differing implementations of standards in various vendor systems and trying to find ways to reconcile them is an expensive, labor-intensive and often painful process. IHE offers a common framework for vendors, IT departments, clinical users and consultants to understand and address clinical integration needs. The IHE technical framework allows flexibility while ensuring that key integration needs are met. IHE promotes integration within and across all units of the healthcare enterprise. The initial successes of IHE were achieved in radiology and the IHE initiative in radiology remains very active. The IHE process has since been adopted in other domains, as well: IT infrastructure, cardiology, laboratory, and medication management. Working in coordination with the others, each of these domains will develop its own technical framework and integration profiles, and implement its own testing and demonstration process. [66].
[66] Integrating the Healthcare Enterprise (IHE); http://www.ihe.net/ |
Interfacing systems is one of the key challenges faced by any healthcare institution’s IT staff. Understanding the differing implementations of standards in various vendor systems and trying to find ways to reconcile them is an expensive, labor-intensive and often painful process.
IHE offers a common framework for vendors, IT departments, clinical users and consultants to understand and address clinical integration needs. The IHE Technical Framework allows flexibility while ensuring that key integration needs are met. [Seite 3] IHE promotes integration within and across all units of the healthcare enterprise. The initial successes of IHE were achieved in radiology, and the IHE initiative in radiology remains very active. The IHE process has since been adopted in other domains, as well: IT Infrastructure, Cardiology, Laboratory, and Medication Management. Working in coordination with the others, each of these domains will develop its own Technical Framework and Integration Profiles, and implement its own testing and demonstration process. |
Die Quelle ist zwar am Ende des Absatzes angegeben (wenn auch unpräzise), trotzdem ist nicht gekennzeichnet, dass der gesamte Absatz wörtlich übernommen ist. |
|
| [33.] Saa/Fragment 026 01 - Diskussion Bearbeitet: 24. November 2014, 20:42 Graf Isolan Erstellt: 6. September 2014, 19:24 (Hindemith) | BauernOpfer, Bishaj 2007, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 26, Zeilen: 1-39 |
Quelle: Bishaj 2007 Seite(n): 4, 5, Zeilen: 4: l. Spalte: 40ff; 5: l. Spalte: 6ff |
|---|---|
| It has a flexible and scalable architecture, where service browsing and human interaction is possible. SLP offers filtered search for attributes and predicates, such as AND, OR, comparators, and substring matching. SLP shares the concept of leasing with Jini and UPnP. Services can be deployed in small networks without any special configuration or deployment. It works even if there is no DNS, DHCP, SLP DA, or routing. Therefore, home networks would benefit much from the automation of service discovery, because they often lack network administration. However, the architecture with DAs makes the system vulnerable to a single point of failure. SLP is an open source, vendor independent and already implemented. It has the advantage of not depending on any programming language.
2.5.4 Bluetooth SDP Bluetooth is a transmission technology, meant for short-range (10m) wireless communication between low-power devices. Bluetooth devices form a personal area network, a piconet, with a maximum of 8 members. Groups of piconets communicating with each-other form a scatternet. Every Bluetooth SDP device has to implement a SDP server that provides services. The server has a list of service records, each with a list of attributes that represent different service classes. A Bluetooth SDP client sends a request message with the list of service classes. Bluetooth is designed for Bluetooth environments, therefore, it offers limited functionality compared to other SDPs. Its functionalities are: search for services by service type; search for services by service attributes; and service browsing without a priori knowledge of the service characteristics. The Bluetooth SDP does not include functionality for accessing services. After services have been discovered with it, the selection, access, and usage can be done with mechanisms out of the scope of SDP, for example by other SDPs such as SLP and Salutation. SDP can coexist with other SDPs, but they are not a necessity. The strong point of Bluetooth in the home environment is the lack of wires, while the short range it provides is a disadvantage. Also, it has a peer-to-peer connectivity, which does not scale well, because typically the systems lack resources. Another disadvantage is the lack of event notification when services become unavailable. The Bluetooth security mechanisms offer either one-way, two-way, or no authentication. When authentication is used, the Bluetooth devices generate a secure connection with a pairing process that makes use of PIN codes entered by users. But for home environment usage, maybe security and privacy have to be addressed also in higher layers. Bluetooth has huge implementation opportunities in home environments. Apart from cell phones and PCs which have already been implemented, there are other potentials. Home automation, for example, could replace doorbells. This would eliminate unnecessary wires around the place. Other goods, such as toys or entertainment devices, could be another area of implementation. |
[Seite 4]
It has a flexible and scalable architecture, where service browsing and human interaction is possible. SLP offers filtered search for attributes and predicates, such as AND, OR, comparators, and substring matching [5]. SLP shares the concept of leasing with Jini and UPnP. Services can be deployed in small networks without any special configuration or deployment. It works even if there is no DNS, DHCP, SLP DA, or routing. Therefore, home networks would benefit much from the automation of service discovery, because they often lack network administration. However, the architecture with DAs makes the system vulnerable to a single point of failure. SLP is an open source, vendor-independent and already implemented [4]. It has the advantage of not depending on any programming language [5]. [Seite 5] 2.6 Bluetooth SDP Bluetooth is a transmission technology, meant for short-range (10m) wireless communication between low-power devices. Bluetooth devices form a personal area network, a piconet, with a maximum of 8 members. Groups of piconets communicating with each-other form a scatternet. Every Bluetooth SDP device has to implement a SDP server that provides services. The server has a list of service records, each with a list of attributes that represent different service classes. A Bluetooth SDP client sends a request message with the list of service classes. Bluetooth is designed for Bluetooth environments, therefore, it offers limited functionality compared to other SDPs. Its functionalities are: search for services by service type; search for services by service attributes; and service browsing without a priori knowledge of the service characteristics. The Bluetooth SDP does not include functionality for accessing services. After services have been discovered with it, the selection, access, and usage can be done with mechanisms out of the scope of SDP, for example by other SDPs such as SLP and Salutation. SDP can coexist with other SDPs, but they are not a necessity [4]. The strong point of Bluetooth in the home environment is the lack of wires, while the short range it provides is a disadvantage. Also, it has a peer-to-peer connectivity, which does not scale well, because typically the systems lack resoures [sic]. Another disadvantage is the lack of event notification when services become unavailable [5]. The Bluetooth security mechanisms offer either one-way, two-way, or no authentication. When authentication is used, the Bluetooth devices generate a secure connection with a pairing process that makes use of PIN codes entered by users. But for home environment usage, maybe security and privacy have to be addressed also in higher layers. Bluetooth has huge implementation opportunities in home environments. Apart from cell phones and PCs which have already been implemented, there are other potentials. Home automation, for example, could replace doorbells. This would eliminate unnecessary wires around the place. Other goods, such as toys or entertainment devices, could be another area of implementation. [4] Christian Bettstetter and Christoph Renner. A Comparison of Service Discovery Protocols and Implementation of the Service Location Protocol. Proc. EUNICE Open European Summer School. September 2000. [5] Choonhwa Lee and Sumi Helal. Protocols for Service Discovery in Dynamic and Mobile Networks. International Journal of Computer Research, 2002. |
Ein Verweis auf die Quelle findet sich am Anfang des Kapitels auf Seite 23. Eine wörtliche Übernahme des gesamten Kapitels wird durch diesen aber in keiner Weise gekennzeichnet. Auf dieser Seite findet sich überhaupt kein Hinweis auf eine Übernahme mehr. |
|
| [34.] Saa/Fragment 025 01 - Diskussion Bearbeitet: 24. November 2014, 14:10 Graf Isolan Erstellt: 6. September 2014, 19:16 (Hindemith) | BauernOpfer, Bishaj 2007, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 25, Zeilen: 1ff (komplett) |
Quelle: Bishaj 2007 Seite(n): 2, 3, 4, Zeilen: 2: l. Spalte: 45ff - r. Spalte 1-3.22-30; 3: r. Spalte 56-58; 4: l. Spalte: 1ff |
|---|---|
| [The] discovery protocol is used when a device looks for a lookup service to register with. The join protocol is used when a service has located the lookup service and wants to join it. The lookup protocol is used when a client needs to locate and invoke a service. Discovery/join is how a service is added to the system. The service provider multicasts a request for local lookup services to identify themselves (discovery). After this, a service object is loaded into the lookup service (joining). This service object has the Java interface for the service including the methods of the interface to be invoked for using the service. There can also be other descriptive attributes. The lookup process ensures that a copy of the service object is loaded into the client. The client can now use the service. Java Remote Method Invocation (RMI) can be used for the communication between services. RMI basically implements the remote procedure call mechanisms in Java. It allows data as well as objects to be passed through the network.
With Jini, administration is still needed, because when a device is introduced to the network, it needs to be assigned an IP. Jini supports distributed events: an object can register its interest in events of another object and be notified whenever these events happen. This adds reliability guarantees to the architecture. Interfaces to devices have to be implemented for the Jini architecture to work. This is a disadvantage for Jini, since other service discovery protocols have them already available for consumer electronics. 2.5.3 SLP SLP [58] is an IETF standard for service discovery. It enables the discovery and selection of a wide range of services accessible through an IP network. With SLP, a user needs only to search for a particular type of service, and optionally for attributes associated with it. It has three major software entities: User Agent (UA), Service Agent (SA), and Directory Agent (DA). The SA advertises the location and attributes of one or more services on behalf of them by using broadcasts. It also replies with IP unicast to requests for these services. The services register and deregister with the SA. Each registrations has a lifetime and reregistration is required periodically. It is the same leasing concept already discussed in previous protocols. The UA receives requests from a client application and forwards multicast requests to SAs. Hence, there is little network overhead for SA discovery. The SA unicasts a response back with the service URL and possible attributes if there is a match with the registered services. The DA is a central information repository and it is optional. Its main function is to improve the performance of SLP. It can be thought of as a tier between the UAs and the SAs, which communicate with the DA instead of with each other. DAs relieve the network traffic from many multicast requests; the effect is more visible in large network, where multicast traffic can increases sharply because there are many SAs and UAs. A DA keeps the SA advertisements, and responds to UA requests. An SA registers itself with a DA. The registration contains the URL for the services, the lifetime, and descriptive attributes of the service. The registration should be refreshed periodically. A UA sends a request message to the DA, which in turn sends a message containing the URL of the service matched against the UA needs. SLP can work both with and without a DA: (1) with DA, information about the services is kept in the DA, so that the UA sends a query there for services; (2) without a DA, the UA multicasts service requests to the network, and a SA offering the service would reply back. In small networks, there may be no real need for a DA. SLP scales well in large networks; the reason is the minimal use of multicast messages [and the fact that it can have multiple DAs.] [58] Choonhwa Lee, Sumi Helal, Protocols for Service Discovery in Dynamic and Mobile Networks. International Journal of Computer Research, 2002. |
[Seite 2]
The discovery protocol is used when a device looks for a lookup service to register with. The join protocol is used when a service has located the lookup service and wants to join it. The lookup protocol is used when a client needs to locate and invoke a service. Discovery/join is how a service is added to the system. The service provider multicasts a request for local lookup services to identify themselves (discovery). After this, a service object is loaded into the lookup service (joining). This service object has the Java interface for the service including the methods of the interface to be invoked for using the service. There can also be other descriptive attributes. The lookup process ensures that a copy of the service object is loaded into the client. The client can now use the service. Java Remote Method Invocation (RMI) can be used for the communication between services [8, 11]. RMI basically implements the remote procedure call mechanisms in Java. It allows data as well as objects to be passed through the network. [...] With Jini, administration is still needed, because when a device is introduced to the network, it needs to be assigned an IP. Jini supports distributed events: an object can register its interest in events of another object and be notified whenever these events happen. This adds reliability guarantees to the architecture. Interfaces to devices have to be implemented for the Jini architecture to work. This is a disadvantage for Jini, since other SDPs have them already available for consumer electronics. [Seite 3] 2.4 SLP SLP [5] is an IETF standard for service discovery. It enables the discovery and selection of a wide range of services ac- [Seite 4] cessible through an IP network. With SLP, a user needs only to search for a particular type of service, and optionally for attributes associated with it. It has three major software entities [5]: User Agent (UA), Service Agent (SA), and Directory Agent (DA). The SA advertises the location and attributes of one or more services on behalf of them by using broadcasts. It also replies with IP unicasts to requests for these services. The services register and deregister with the SA. Each registrations has a lifetime and reregistration is required periodically. It is the same leasing concept already discussed in previous protocols. The UA receives requests from a client application and forwards multicast requests to SAs. Hence, there is little network overhead for SA discovery. The SA unicasts a response back with the service URL and possible attributes if there is a match with the registered services. DA is a central information repository and it is optional. Its main function is to improve the performance of SLP. It can be thought of as a tier between the UAs and the SAs, which comminicate [sic] with the DA instead of with each-other [sic]. DAs relieve the network traffic from many multicast requests; the effect is more visible in large network, where multicast traffic can increases sharply because there are many SAs and UAs. A DA keeps the SA advertisements, and responds to UA requests. An SA registers itself with a DA. The registration contains the URL for the services, the lifetime, and descriptive attributes of the service. The registration should be refreshed periodically. A UA sends a request message to the DA, which in turn sends a message containig the URL of the service matched against the UA needs. SLP can work both with and without a DA: (1) with DA, information about the services is kept in the DA, so that the UA sends a query there for services; (2) without a DA, the UA multicasts service requests to the network, and a SA offering the service would reply back [5]. In small networks, there may be no real need for a DA. SLP scales well in large networks; the reason is the minimal use of multicast messages and the fact that it can have multiple DAs. [5] Choonhwa Lee and Sumi Helal. Protocols for Service Discovery in Dynamic and Mobile Networks. International Journal of Computer Research, 2002. [8] Sun Microsystems. Jini Architecture Specification, version 1.2, December 2001. http: //www.sun.com/software/jini/specs/jini1.2html/jini-title.html, 09 April 2007. [11] Jim Waldo. The Jini architecture for network-centric computing. Communications of the ACM, July 1999. |
Ein Verweis auf die Quelle findet sich am Anfang des Kapitels auf Seite 23. Eine wörtliche Übernahme des gesamten Kapitels wird durch diesen aber in keiner Weise gekennzeichnet. |
|
| [35.] Saa/Fragment 024 01 - Diskussion Bearbeitet: 23. November 2014, 18:44 Graf Isolan Erstellt: 6. September 2014, 16:35 (Hindemith) | BauernOpfer, Bishaj 2007, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 24, Zeilen: 1ff (komplett) |
Quelle: Bishaj 2007 Seite(n): 1, 2, 3, Zeilen: 1: r. Spalte: 25-42; 2: l. Spalte: 1-19.21ff.; 3: l. Spalte: 25-30.40ff. |
|---|---|
| [XML is used in UPnP in device and service descriptions, control] messages and eventing. The advertisement message that a device issues contains a URL that directs to an XML file in the network, which describes the capabilities of the device. Each UPnP device must be a DHCP client and search for a DHCP server when connected to a network. In the lack of a DHCP server it must use Auto IP to get an address: the device randomly chooses an address, and then makes an ARP request to see if it is already occupied. This mechanism minimizes administration requirements.
2.5.2 Jini Jini [57] is a network architecture for distributed systems, developed by Sun Microsystems in Java. The aim of this architecture is to make the network dynamic and self-administered, where services are added and deleted in a flexible manner. More precisely, the purpose is to end up with a monolithic system where users are able to not only share services and resources in a network, but have easy access to the services, even though the user's location may change. In a way, Jini can be considered as an extension of the Java application environment from a single machine to the whole network. Jini is based on Java environment, which offers built-in security for executing code from another machine and adds functionality on top of that to support the moving of components in a distributed system, as compared to the easy movement of objects in a Java application environment. Jini makes the assumption that the devices connected to the network have a certain memory capacity and processing power. The limitation on the devices that can be connected directly to the network is a Java legacy; the devices need to have the JVM. Other devices not meeting this criteria need to be presented to the network by means of a proxy, which is a piece of hardware and/or software that meets the above-mentioned requirements. The service proxy has the drawback that in order to have no need for drivers, manufacturers must agree to a common interface. This is hard to achieve for every kind of device, and is exacerbated by the fact that each device tends to encompass multiple and different functionalities. There is benefit from the JVM: it makes Jini platform independent, but the JVM is heavy for hand-held devices and embedded systems. As for Java, Jini depends on the Java application environment, rather than on the Java programming language. Any language, as claimed, producing compliant bytecode can be used. However, practically, only the Java language is used. Services are crucial to the Jini architecture. They can be used by a person, a program, or another service. Some examples of services are: storage, a computation, a hardware device, a user, devices such as printers, software such as applications, information such as databases. A Jini system is made up of services that can be collected in order to complete a particular task. A service can use another service, a client may be a service for another client. A service protocol is used for the communication between services. The one Jini offers is a set of interfaces that define critical service interaction between services. It can be extended further. A lookup service is used to find and resolve services. What it does is a mapping of the interfaces that indicate the functionality of a service to sets of objects implementing the service. A service has to be registered in at least one lookup service. A Jini service provider registers itself with every discovered lookup service. An object can itself consist of other services, this makes room for hierarchical services and lookup. Furthermore, objects may also be the encapsulation of other naming or directory services. References to the Jini lookup system can also be placed in other naming and directory services. In this way, bridging between the Jini lookup system and other forms of lookup service is created. The discovery, join and lookup protocols are the heart of the Jini architecture. [57] Sun Microsystems; Jini Architecture Specification, version 1.2, December 2001. http://www.sun.com/software/jini/specs/jini1.2html/ jini-title.html, 09 April 2007. |
2.1 Jini
Jini [8] is a network architecture for distributed systems; it is developed by Sun Microsystems in Java. The aim of this architecure [sic] is to make the network dynamic and self-administered, where services are added and deleted in a flexible manner. More precisely, the purpose is to end up with a system where users are able to share services and resources in a network; where users have easy access to the services, even though the user’s location may change; where building, maintaining, and changing devices, software, or users is made simple. In a way, Jini can be considered as an extension of the Java application environment from a single machine to the whole network. The Java environment, on which Jini is based, offers built-in security for executing code from another machine. Jini adds functionality on top of that to support the moving of components in a distributed system, as compared to the easy movement of objects in a Java application environment. [Seite 2] Jini makes the assumption that the devices connected to the network have a certain memory capacity and processing power. The limitation on the devices that can be connected directly to the network is a Java legacy; the devices need to have the JVM. Other devices not meeting this criteria need to be presented to the network by means of a proxy, which is a piece of hardware and/or software that meets the abovementioned requirements. The service proxy has the drawback that in order to have no need for drivers, manufacturers must agree to a common interface. This is hard to achieve for every kind of device, and is exacerbated by the fact that each device tends to encompass multiple and different functionalities. There is benefit from the JVM: it makes Jini platform-independent, but the JVM is heavy for handheld devices and embedded systems. As for Java, Jini depends on the Java application environment, rather than on the Java programming language. Any language, as claimed, producing compliant bytecodes can be used. However, practically, only the Java language is used. [...] Services are crucial to the Jini architecture [8, 11]. They can be used by a person, a program, or another service. Some examples of services are: storage, a computation, a hardware device, a user, devices such as printers, software such as applications, information such as databases. A Jini system is made up of services that can be collected in order to complete a particular task. A service can use another service, a client may be a service for another client. A service protocol is used for the communication between services. The one Jini offers is a set of interfaces that define critical service interaction between services. It can be extended further. A lookup service is used to find and resolve services. What it does is a mapping of the interfaces that indicate the functionality of a service to sets of objects implementing the service. A service has to be registered in at least one lookup service. A Jini service provider registers itself with every discovered lookup service [3]. An object can itself consist of other services, this makes room for hierarchical services and lookup. Furthermore, objects may also be the encapsulation of other naming or directory services. References to the Jini lookup system can also be placed in other naming and directory services. In this way, bridging between the Jini lookup system and other forms of lookup service is created. The discovery, join and lookup protocols are the heart of the Jini architecture [8].
XML is used in UPnP in device and service descriptions, control messages and eventing. The advertisement message that a device issues contains a URL that directs to an XML file in the network, which describes the capabilities of the device [3]. [...] Each UPnP device must be a DHCP client and search for a DHCP server when connected to a network. In the lack of a DHCP server it must use Auto IP to get an address: the device randomly chooses an address, and then makes an ARP request to see if it is already occupied. This mechanism minimizes administration requirements. [3] Adrian Friday, Nigel Davies, Nat Wallbank, Elaine Catterall and Stephen Pink. Supporting Service Discovery, Querying and Interaction in Ubiquitous Computing Environments. Wireless Networks 10, 631-641, 2004. [8] Sun Microsystems. Jini Architecture Specification, version 1.2, December 2001. http://www.sun.com/software/ jini/specs/jini1.2html/ jini-title.html, 09 April 2007. [11] Jim Waldo. The Jini architecture for network-centric computing. Communications of the ACM, July 1999. |
Ein Verweis auf die Quelle findet sich am Anfang des Kapitels auf Seite 23. Eine wörtliche Übernahme des gesamten Kapitels wird durch diesen aber in keiner Weise gekennzeichnet. Mit der Web-Adresse hat Saa auch das Datum der letzten Einsichtnahme ("09 April 2007") aus der Vorlage kopiert. |
|
| [36.] Saa/Fragment 022 01 - Diskussion Bearbeitet: 23. November 2014, 05:55 Hindemith Erstellt: 7. September 2014, 15:24 (Graf Isolan) | Cabral et al 2004, Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 22, Zeilen: 1-25 |
Quelle: Cabral et al 2004 Seite(n): 235, Zeilen: 9ff |
|---|---|
| WSMF is the product of research on modeling of reusable knowledge components. WSMF is centered on two complementary principles: a strong de-coupling of the various components that realize an e-commerce application; and a strong mediation service enabling Web Services to communicate in a scalable manner. The mediation is applied at several levels: mediation of data structures; mediation of business logics; mediation of message exchange protocols; and mediation of dynamic service invocation. WSMF consists of four main elements: ontologies that provide the terminology used by other elements; goal repositories that define the problems that should be solved by Web Services; Web Services descriptions that define various aspects of a Web Service; and mediators which bypass interoperability problems.
WSMF implementation has been assigned to two main projects: Semantic Web enabled Web Services (SWWS) [53], and Web Service Modeling Ontology (WSMO) [54]. SWWS provides a description framework, a discovery framework and a mediation platform for Web Services, according to a conceptual architecture. WSMO refines the Web Services Modeling Framework and develops a formal service ontology and language for SWS. WSMO Service Ontology includes definitions for goals, mediators and Web Services. The underlying representation language for WSMO is F-logic because it is a full first order logic language that provides second order syntax while staying in the first order logic semantics, and has a minimal model semantics. The main characterizing feature of the WSMO architecture is that the goal, Web Service and ontology components are linked by four types of mediators as follows: • OO mediators link ontologies to ontologies • WW mediators link Web Services to Web Services • WG mediators link Web Services to goals • GG mediators link goals to goals. [53] Semantic Web enabled Web Services (SWWS); http://swws.semanticweb.org/ [54] Web Service Modeling Ontology (WSMO); http://www.wsmo.org/ |
WSMF is the product of research on modelling of reusable knowledge components [10].
WSMF is centered on two complementary principles: a strong de-coupling of the various components that realize an e-commerce application; and a strong mediation service enabling Web services to communicate in a scalable manner. Mediation is applied at several levels: mediation of data structures; mediation of business logics; mediation of message exchange protocols; and mediation of dynamic service invocation. WSMF consists of four main elements: ontologies that provide the terminology used by other elements; goal repositories that define the problems that should be solved by Web services; Web services descriptions that define various aspects of a Web service; and mediators which bypass interoperability problems. WSMF implementation has been assigned to two main projects: Semantic Web enabled Web Services (SWWS) [25]; and WSMO (Web Service Modelling Ontology) [28]. SWWS will provide a description framework, a discovery framework and a mediation platform for Web Services, according to a conceptual architecture. WSMO will refine WSMF and develop a formal service ontology and language for SWS. WSMO service ontology includes definitions for goals, mediators and web services. A web service consists of a capability and an interface. The underlying representation language for WSMO is F-logic. The rationale for the choice of F-logic is that it is a full first order logic language that provides second order syntax while staying in the first order logic semantics, and has a minimal model semantics. The main characterizing feature of the WSMO architecture is that the goal, web service and ontology components are linked by four types of mediators as follows: • OO mediators link ontologies to ontologies, • WW mediators link web services to web services, • WG mediators link web services to goals, and finally, • GG mediators link goals to goals. 10. Fensel, D. and Motta, E.: Structured Development of Problem Solving Methods. IEEE Transactions on Knowledge and Data Engineering, Vol. 13(6). (2001). 913-932. 25. SWWS Consortium. Report on Development of Web Service Discovery Framework. October 2003. http://swws.semanticweb.org/public_doc/D3.1.pdf 28. WSMO Working Group. Web Service Modelling Ontology Project. DERI Working Drafts. http://www.nextwebgeneration.org/projects/wsmo/ (2004) |
Fast vollständig wörtlich übereinstimmend, aber dennoch ohne Hinweis auf eine Übernahme. (Sichtung mit [1], Zeilenangaben der Quelle daher nicht überprüft) |
|
| [37.] Saa/Fragment 021 47 - Diskussion Bearbeitet: 23. November 2014, 05:53 Hindemith Erstellt: 7. September 2014, 15:05 (Graf Isolan) | Cabral et al 2004, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 21, Zeilen: 47 |
Quelle: Cabral et al 2004 Seite(n): 235, Zeilen: 6ff |
|---|---|
| WSML
The Web Service Modeling Framework (WSMF) [50] provides a conceptual model and a formal language WSML (Web Service Modeling Language) for the semantic markup of Web Services together with a reference implementation WSMX (Web Service Execution Environment). Its main goal is to fully enable e-Commerce by applying Semantic Web [technology to Web Services.] [50] Fensel, D., Bussler, C. The Web Service Modeling Framework (WSMF). Eletronic Commerce: Research and Applications. Vol. 1. pp. 113-137, 2002 |
7 WSMF approach
The Web Service Modeling Framework (WSMF) [9] provides a model for describing the various aspects related to Web services. Its main goal is to fully enable e-commerce by applying Semantic Web technology to Web services. 9. Fensel, D., Bussler, C. The Web Service Modeling Framework WSMF. Eletronic Commerce: Research and Applications. Vol. 1. (2002). 113-137 |
Ohne Hinweis auf eine Übernahme. Diese wird auf der nächsten Seite fortgesetzt (vgl. Fragment 022 01). (Sichtung mit [2], Zeilenangaben der Quelle daher nicht überprüft) |
|
| [38.] Saa/Fragment 111 02 - Diskussion Bearbeitet: 23. November 2014, 05:49 Hindemith Erstellt: 10. September 2014, 14:04 (Graf Isolan) | Blood Pressure Monitors Report 2008, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 111, Zeilen: 2-9 |
Quelle: Blood Pressure Monitors Report 2008 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| 8.1.7 Digital Blood Pressure Monitor - A&D Medical UA-767PC
Electronic or digital blood pressure monitors for home use are either semi-automatic manual inflation (the user squeezes the bulb to inflate the cuff) or automatic inflation. Automatic monitors have everything contained in one unit, so they're easier to handle than systems with a separate gauge and stethoscope. Most home blood pressure monitors are portable and have a D-ring cuff for one-handed application, which may fit around the wrist or upper arm. Also, expensive monitors have automatic inflation and deflation systems, along with large, easy-to-read digital displays and error indicators, and built-in pulse (heart rate) measurement. |
Electronic/digital blood pressure monitors for home use are either semiautomatic manual inflation (you squeeze the bulb to inflate the cuff) or automatic inflation. Automatic monitors have everything contained in one unit, so they're easier to handle than systems with a separate gauge and stethoscope. Most home blood pressure monitors are very portable and have a D-ring cuff for one-handed application. The cuff may fit around the wrist or arm. More expensive monitors have automatic inflation and deflation systems, along with large, easy-to-read digital displays and error indicators, reading printouts and built-in pulse (heart rate) measurement. |
Ohne Hinweis auf eine Übernahme. |
|
| [39.] Saa/Fragment 107 28 - Diskussion Bearbeitet: 23. November 2014, 05:46 Hindemith Erstellt: 9. September 2014, 16:13 (Graf Isolan) | Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop, Sherman Oaks Medical Supplies 2008 |
|
|
|
| Untersuchte Arbeit: Seite: 107, Zeilen: 28-31 |
Quelle: Sherman Oaks Medical Supplies 2008 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| A Pulse Oximeter is a medical device that indirectly measures the oxygen saturation of a patient's blood (as opposed to measuring oxygen saturation directly through a blood sample) and changes in blood volume in the skin by producing a photoplethysmograph. It is often attached to a medical monitor so the staff could see a patient's oxygenation at [all times.] | A Pulse Oximeters [sic] is a medical device that indirectly measures the Oxygen saturation of a patient's blood (as opposed to measuring Oxygen saturation directly through a blood sample) and changes in blood volume in the skin, producing a photoplethysmograph. It is often attached to a medical monitor so staff can see a patient's oxygenation at all times. |
Ohne Hinweis auf eine Übernahme. Die hier wiedergegebene Quelle dient nur als Beispiel. Die Formulierungen sind ubiquitär im WWW zu finden (u.a. auch in der englisch-sprachigen Wikipedia) und stammen nicht von Saa. |
|
| [40.] Saa/Fragment 033 01 - Diskussion Bearbeitet: 23. November 2014, 05:09 Hindemith Erstellt: 5. September 2014, 17:03 (Graf Isolan) | Fragment, Gesichtet, Mylonas 2004, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 33, Zeilen: 1-27, 33-34 |
Quelle: Mylonas 2004 Seite(n): 56, 57, Zeilen: 56:3-7.9-20; 57:1-7.11-16 |
|---|---|
| Modern hospitals have at least two data processing systems, one system for finances and general administration, while the other for patient administration and basic patient data (demographics, diagnoses and procedures) [67]. In many cases there are other systems, which are often dedicated departmental systems e.g. system in chemical lab, system(s) in radiology department (RIS and PACS), ICU patient data management system, etc. These data processing systems are dedicated to the processes internal to the departments and in many cases they deal with device data, e.g. control of the analytic equipment in the chemical lab and collection of measurement data, collection and storage of radiological pictures, collection of measurement data of patient monitoring and therapeutic devices in ICU. These systems normally communicate in two different directions, one to devices, and one to hospital information system (HIS). The data collected from devices, images, waveforms, etc. must be readable for machinery and not necessarily be readable by humans. Often this data is understandable by humans only if available in the graphical representation. Nevertheless, these systems communicate with the HIS too in order to receive e.g. demographic data of patients. That can be described by different levels of communication, the HIS or enterprise level, and the departmental or device level.
In fact, communication to the HIS and communication with devices is rather different in nature and indeed there are big differences between e.g. the communication with radiology machinery and to devices in the ICU. The data representation and communication requirements are very different between these domains, e.g., the radiology images to communicate and store are rather huge, while the messages in ICU device communication are rather small compared to image communication. The ICU device communication needs alert messages and real time communication. In Fig. 2.8, the communication of HIS or enterprise level, as well as the departmental or device level is shown. The Domain/Enterprise Level concerns the communication in the whole hospital, communication between different hospitals, and exchange with health care professionals outside the hospital and with health care organizations. [...] The communication on Device/Departmental Level is mostly limited to a single department or parts of a single department (ICU) only. [67] Strategies for harmonization and integration of device-level and enterprise-wide methodologies for communication as applied to HL7-LOINC and ENV 13734; Final document approved by CEN/TC 251 2001-09-18 |
[Seite 56]
Communication Domain Model Modern hospitals have at least two Data Processing Systems, one system for finances and general administration and one system for patient administration and basic patient data (demographics, diagnoses and procedures). In many cases there are other systems, often dedicated departmental systems e.g. system in chemical lab, system(s) in radiology department (RIS and PACS), ICU patient data management (documentation) system, etc. [...] Departments and communication structure in hospitals These data processing systems are dedicated to the processes internal to the departments. In many cases the systems deal with device data, e.g. control of the analytic equipment in the chemical lab and collection of measurement data, collection and storage of radiological pictures, collection of measurement data of patient monitoring and therapeutic devices in ICU. These systems normally communicate in two different directions: one to devices, one to hospital information system. The data collected from devices, images, waveforms, etc. must be readable for machinery and not necessarily be readable by humans. Often these data are understandable by humans only in graphical representation. Nevertheless these systems communicate in the hospital information system also. They receive e.g. demographic data of patients from the HIS. That can be described by different levels of communication, the hospital information system (HIS) level or enterprise level and the departmental or device level. [Seite 57] In fact communication to the HIS and communication with devices is rather different in nature and indeed there are big differences between e.g. the communication with radiology machinery and to devices in ICU. Data representation and communication requirements are very different between these "domains". Some examples: Radiology images to communicate and store are rather huge, messages in ICU device communication are rather small compared to image communication. ICU device communication needs alert messages and real time communication. [...] The HIS or enterprise level of communication is shown above the departmental or device level of communication in figure 3. The reason is that the domain on enterprise level concerns communication in the whole hospital, communication between different hospitals, and exchange with health care professionals outside the hospital and with health care organisations. The communication on device or departmental level is mostly limited to a single department or parts of a single department (ICU) only. |
Ohne Hinweis auf eine Übernahme. |
|
| [41.] Saa/Fragment 021 03 - Diskussion Bearbeitet: 23. November 2014, 05:00 Hindemith Erstellt: 7. September 2014, 00:12 (Graf Isolan) | Cabral et al 2004, Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 21, Zeilen: 3-42 |
Quelle: Cabral et al 2004 Seite(n): 234-235, Zeilen: 234:3ff - 235:1ff |
|---|---|
| OWL-S
OWL-S [49] is an upper ontology used to describe the semantics of services based on the W3C standard ontology OWL and is grounded in WSDL. Its approach originated from an Artificial Intelligence background and has previously been used to describe agent functionality within several multi-agent systems as well as with a variety of planners to solve higher level goals. It consists of three main upper ontologies: the Profile, Process Model and Grounding. The Profile is used to describe services for the purposes of discovery; service descriptions and queries are constructed from a description of functional properties (i.e. inputs, outputs, preconditions, and effects - IOPEs), and non-functional properties (human oriented properties such as service name, etc, and parameters for defining additional meta data about the service itself, such as concept type or quality of service). In addition, the profile class can be sub-classed and specialized, thus supporting the creation of profile taxonomies which subsequently describe different classes of services. The Process Models describe the composition or orchestration of one or more services in terms of their constituent processes. This is used both for reasoning about possible compositions (such as validating a possible composition, determining if a model is executable given a specific context, etc) and controlling the enactment/invocation of a service. Three process classes have been defined: the composite, simple and atomic process. The atomic process is a single, black-box process description with exposed IOPEs. Inputs and Outputs relate to data channels, where data flows between processes. The preconditions specify facts of the world that must be asserted in order for an agent to execute a service. Effects characterize the facts that become asserted given a successful execution of the service, such as the physical side-effects that the execution the service has on the physical world. The simple process provides a means of describing service or process abstractions, which means that such elements have no specific binding to a physical service, and thus have to be realized by an atomic process (e.g. through service discovery and dynamic binding at run-time), or expanded into a composite process. The composite processes are hierarchically defined work-flows, consisting of atomic, simple and other composite processes. These process work-flows are constructed using a number of different composition constructs, including: Sequence; Unordered; Choice; If then else; Iterate; Repeat until; Repeat while; Split, and Split + join. The profile and process models provide semantic frameworks whereby services can be discovered and invoked, based upon conceptual descriptions defined within Semantic Web (i.e. OWL) ontologies. The Grounding provides a pragmatic binding between this concept space and the physical data/machine/port space, thus facilitating service execution. The process model is mapped to a WSDL description of the service, through a thin grounding. Each atomic process is mapped to a WSDL operation, and the OWL-S properties used to represent inputs and outputs are grounded in terms of XML data types. Additional properties pertaining to the binding of the service are also provided (i.e. the IP address of the machine hosting the service, and the ports used to expose the service). [49] OWL-S Semantic Markup for Web Services; http://www.w3.org/Submission/OWL-S/ |
[Seite 234]
6 OWL-S approach OWL-S (previously DAML-S [9]) consists of a set of ontologies designed for describing and reasoning over service descriptions. OWL-S approach originated from an AI background and has previously been used to describe agent functionality within several Multi-Agent Systems as well as with a variety of planners to solve higher level goals. OWL-S combines the expressivity of description logics (in this case OWL) and the pragmatism found in the emerging Web Services Standards, to describe services that can be expressed semantically, and yet grounded within a well defined data typing formalism. It consists of three main upper ontologies: the Profile, Process Model and Grounding. The Profile is used to describe services for the purposes of discovery; service descriptions (and queries) are constructed from a description of functional properties (i.e. inputs, outputs, preconditions, and effects - IOPEs), and non-functional properties (human oriented properties such as service name, etc, and parameters for defining additional meta data about the service itself, such as concept type or quality of service). In addition, the profile class can be subclassed and specialized, thus supporting the creation of profile taxonomies which subsequently describe different classes of services. OWL-S process models describe the composition or orchestration of one or more services in terms of their constituent processes. This is used both for reasoning about possible compositions (such as validating a possible composition, determining if a model is executable given a specific context, etc) and controlling the enactment/invocation of a service. Three process classes have been defined: the composite, simple and atomic process. The atomic process is a single, black-box process description with exposed IOPEs. Inputs and outputs relate to data channels, where data flows between processes. Preconditions specify facts of the world that must be asserted in order for an agent to execute a service. Effects characterize facts that become asserted given a successful execution of the service, such as the physical side-effects that the execution the service has on the physical world. Simple processes provide a means of describing service or process abstractions – such elements have no specific binding to a physical service, and thus have to be realized by an atomic process (e.g. through service discovery and dynamic binding at run-time), or expanded into a composite process. Composite processes are hierarchically defined workflows, consisting of atomic, simple and other composite processes. These process workflows are constructed using a number of different composition constructs, including: Sequence, Unordered, Choice, If-then-else, Iterate, Repeat-until, Repeat-while, Split, and Split+join. The profile and process models provide semantic frameworks whereby services can be discovered and invoked, based upon conceptual descriptions defined within Semantic Web (i.e. OWL) ontologies. The grounding provides a pragmatic binding between this concept space and the physical data/machine/port space, thus facilitating service execution. The process model is mapped to a WSDL description of the ser- [Seite 235] vice, through a thin grounding. Each atomic process is mapped to a WSDL operation, and the OWL-S properties used to represent inputs and outputs are grounded in terms of XML data types. Additional properties pertaining to the binding of the service are also provided (i.e. the IP address of the machine hosting the service, and the ports used to expose the service). 8. DAML-S Coalition: DAML-S 0.9 Draft Release. http://www.daml.org/services/damls/0.9/. (2003) 9. Fensel, D., Bussler, C. The Web Service Modeling Framework WSMF. Eletronic Commerce: Research and Applications. Vol. 1. (2002). 113-137 19. OWL-S Coalition: OWL-S 1.0 Release. http://www.daml.org/services/owl-s/1.0/. (2003) |
Ohne Hinweis auf eine Übernahme. |
|
| [42.] Saa/Fragment 009 16 - Diskussion Bearbeitet: 23. November 2014, 04:52 Hindemith Erstellt: 5. September 2014, 11:25 (Graf Isolan) | BauernOpfer, Cabral et al 2004, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 9, Zeilen: 16-20, 23-26 |
Quelle: Cabral et al 2004 Seite(n): 225, Zeilen: 25-26, 30-37 |
|---|---|
| 2.1 Web Services
In recent years, distributed programming paradigms have been [sic] emerged that allow generic software components to be developed and shared. Although ideal for some enterprise integration and e-Commerce, it has only been with the adoption of XML as a common data syntax that the underlying principles have gained wide scale adoption, through the definition of Web Service standards. According to the definition of W3C, "A Web Service is a software application identified by a URI, whose interfaces and bindings are capable of being defined, described, and discovered as XML artifacts" [31]. Web Services are well defined, reusable, software components that perform specific, encapsulated tasks via standardized Web-oriented mechanisms. They can be discovered, invoked, and the composition of several services can be choreographed, using well defined workflow modeling frameworks. [31] L. Cabral et al.; Approaches to Semantic Web Services: An Overview and Comparison [sic]; LNCS 3053, pp. 225-239, 2004 |
Approaches to Semantic Web Services: An Overview and Comparisons
[...] 1 Introduction In recent years, distributed programming paradigms have emerged, that allow generic software components to be developed and shared. [...] Although ideal for some enterprise integration and eCommerce, it has only been with the adoption of XML as a common data syntax that the underlying principals [sic] have gained wide scale adoption, through the definition of Web Service standards. Web services are well defined, reusable, software components that perform specific, encapsulated tasks via standardized Web-oriented mechanisms. They can be discovered, invoked, and the composition of several services can be choreographed, using well defined workflow modeling frameworks. |
Art und Umfang der Übernahme bleiben ungekennzeichnet. Die als Zitat gekennzeichnete Definition ist zwar korrekt, findet sich allerdings nicht einmal annähernd in der genannten Quelle: Cabral et al. stellen nur fest (S. 227): Die zitierte Definition findet man z.B. hier. |
|
| [43.] Saa/Fragment 017 19 - Diskussion Bearbeitet: 23. November 2014, 04:46 Hindemith Erstellt: 5. September 2014, 07:53 (Graf Isolan) | Cabral et al 2004, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 17, Zeilen: 19-43 |
Quelle: Cabral et al 2004 Seite(n): 230, Zeilen: 11ff |
|---|---|
| 2.4.1 Why Semantic Web Services?
Semantic descriptions of Web Services are necessary in order to enable their automatic discovery, composition and execution across heterogeneous users and domains. Present technologies for Web Services provide descriptions only at the syntactic level, which makes it diffcult [sic] for the requesters and providers to interpret or represent nontrivial statements, i.e. the meaning of inputs and outputs or applicable constraints. This limitation may be relaxed by providing a rich set of semantic annotations that augment the service description. A Semantic Web Service is defined through a service ontology, which enables machine interpret-ability of its capabilities as well as integration with domain knowledge. The deployment of Semantic Web Services will rely on the further development and combination of Web Services and Semantic Web enabling technologies. Several initiatives have been started in the industry and academia, e.g. DIP [45], SWSI [46] which are investigating solutions for the main issues regarding the infrastructure for SWS. Fig. 2.4 shows the following three orthogonal dimensions as characterization of Semantic Web Service infrastructure: • Usage activities define the functional requirements, which a framework for Semantic Web Services ought to support. • Architecture of SWSs describes the components needed for accomplishing the activities defined for SWS. • Service ontology aggregates all concept models related to the description of a Semantic Web Service and constitutes the knowledge-level model of the information describing and supporting the usage of the service. Usage Activities From the usage activities perspective, SWS are seen as objects within a business application execution scenario. The activities required for running an application using SWS [include: publishing, discovery, selection, composition, invocation, deployment and ontology management, as described next.] [45] Data, Information and Process Integration with Semantic Web Services (DIP); http://dip.semanticweb.org [46] Semantic Web Service Initiative (SWSI); http://www.swsi.org |
4 Semantic Web Services
Semantic descriptions of Web services are necessary in order to enable their automatic discovery, composition and execution across heterogeneous users and domains. Existing technologies for Web services only provide descriptions at the syntactic level, making it difficult for requesters and providers to interpret or represent nontrivial statements such as the meaning of inputs and outputs or applicable constraints. This limitation may be relaxed by providing a rich set of semantic annotations that augment the service description. A Semantic Web Service is defined through a service ontology, which enables machine interpretability of its capabilities as well as integration with domain knowledge. The deployment of Semantic Web Services will rely on the further development and combination of Web Services and Semantic Web enabling technologies. There exist several initiatives (e.g. http://dip.semanticweb.org or http://www.swsi.org) taking place in industry and academia, which are investigating solutions for the main issues regarding the infrastructure for SWS. Semantic Web Service infrastructures can be characterized along three orthogonal dimensions (fig. 4): usage activities, architecture and service ontology. These dimensions relate to the requirements for SWS at business, physical and conceptual levels. Usage activities define the functional requirements, which a framework for Semantic Web Services ought to support. The architecture of SWS defines the components needed for accomplishing these activities. The service ontology aggregates all concept models related to the description of a Semantic Web Service, and constitutes the knowledge-level model of the information describing and supporting the usage of the service. From the usage activities perspective, SWS are seen as objects within a business application execution scenario. The activities required for running an application using SWS include: publishing, discovery, selection, composition, invocation, deployment and ontology management, as described next. |
Ohne Hinweis auf eine Übernahme. |
|
| [44.] Saa/Fragment 046 15 - Diskussion Bearbeitet: 21. September 2014, 21:45 Hindemith Erstellt: 9. September 2014, 10:47 (Hindemith) | Fragment, Gesichtet, SMWFragment, Saa, Sarnovsky et al 2007, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 46, Zeilen: 15-21 |
Quelle: Sarnovsky et al 2007 Seite(n): 2, 3, Zeilen: 2: 3-5; 3: 10-12 |
|---|---|
| The vision of the HYDRA project is to create the most widely deployed middleware for intelligent networked embedded systems that will allow producers to develop cost-effective and innovative embedded applications for new and already existing heterogeneous physical devices. The embedded and mobile Service-Oriented Architecture will provide interoperable access to data, information and knowledge across heterogeneous platforms, including Web Services, and support true ambient intelligence for ubiquitous networked devices. | To create the most widely deployed middleware for intelligent networked embedded systems that will allow producers to develop cost-effective and innovative embedded applications for new and already existing devices.
[Seite 3] The embedded and mobile Service-oriented Architecture will provide interoperable access to data, information and knowledge across heterogeneous platforms, including web services, and support true ambient intelligence for ubiquitous networked devices. |
Ein Verweis auf die Quelle fehlt hier. |
|
| [45.] Saa/Fragment 058 09 - Diskussion Bearbeitet: 21. September 2014, 21:45 Hindemith Erstellt: 7. September 2014, 22:02 (Hindemith) | Fragment, Gesichtet, Klusch 2006b, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 58, Zeilen: 9-13 |
Quelle: Klusch 2006b Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| SCALLOPS provides means of Semantic Web Service discovery via middle agents such as brokers and matchmakers, which adapt to the non-deterministically changing environment, where agents and services may enter or leave at any time. Therefore, SCALLOPS agents are able to interleave service composition planning with service discovery to find alternative services provided by other agents. | SCALLOPS will provide means of semantic Web service discovery via middle agents such as brokers and matchmakers, which adapt to the non-deterministically changing environment, where agents and services may enter or leave at any time. Therefore, SCALLOPS agents are able to interleave service composition planning with service discovery to find alternative services provided by other agents. |
Ein Verweis auf die Quelle fehlt. |
|
| [46.] Saa/Fragment 058 01 - Diskussion Bearbeitet: 21. September 2014, 21:45 Hindemith Erstellt: 7. September 2014, 21:49 (Hindemith) | Fragment, Gesichtet, Klusch 2006, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 58, Zeilen: 1-7 |
Quelle: Klusch 2006 Seite(n): 1 (Internetquelle), Zeilen: - |
|---|---|
| [The results of both kinds of negotiations enable the HI agent to make its decision through individually] composed health care expense approval service of Mikka's insurance fund according to his membership status. In this scenario, the HI agent confirms full coverage of expenses for local treatment and recreation in Stockholm, as well as return flight, but no emergency transport with escort back home.
Finally, after two weeks treatment in the hospital and one week of full recovery in a recreation area in the outer bound of Stockholm selected by his insurance fund, Mikka returns to Helsinki and continues his summer vacation with his family. |
The results of both kinds of negotiations enable the HI agent to make its decision through individually composed health care expense approval service of Mikka's insurance fund according to his membership status. In this scenario, the HI agent confirms full coverage of expenses for local treatment and recreation in Stockholm, as well as return flight, but no emergency transport with escort back home.
Finally, after two weeks treatment in the hospital and one week of full recovery in a recreation area in the outer bound of Stockholm selected by his insurance fund, Mikka returns to Helsinki and continues his summer vacation at Savitaipale in central Finland with his family. |
Ein Verweis auf die Quelle fehlt. |
|
| [47.] Saa/Fragment 045 01 - Diskussion Bearbeitet: 21. September 2014, 21:45 Hindemith Erstellt: 7. September 2014, 09:29 (Hindemith) | Eisenhauer et al 2007, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 45, Zeilen: 1-17 |
Quelle: Eisenhauer et al 2007 Seite(n): 17, 18, Zeilen: 17: 20ff; 18: 1ff |
|---|---|
| These components have a limited set of functionality but could also be deployed on another machine acting as a proxy for e.g. a mote where it would be highly unlikely that those managers would ever be deployed on such a resource-limited device. They have been put on the device by a device manufacturer to provide certain functions irrespective of which application is using the device.
The HYDRA middleware elements are enclosed by the physical and the application layer shown at the bottom and at the top of the diagram respectively. The physical layer realizes several network connections like ZigBee, Bluetooth or WLAN. The application layer contains user applications which could contain modules like workflow management, user interface, custom logic and configuration details. These two layers are not part of the HYDRA middleware. The middleware itself consists of three layers - the network, service and semantic layer, where each layer holds elements according to their functionality and purpose. It is to be noted that some device elements have similar and thus likewise named, counterparts among the application elements. Both, device and application elements, have a Security Manager, which is an orthogonal service and depicted as vertical to cover all three middleware layers. |
Those components have a limited set of functionality but could also be deployed on another machine acting as a proxy for e.g. a mote where it would be highly unlikely that those managers would ever be deployed on such a resource-limited device. They have been put on the device by a device manufacturer to provide certain functions irrespective of which application is using the device.
[Seite 18] The Hydra middleware elements are enclosed by the physical, operating system and the application layer shown at the bottom and at the top of the diagram respectively. The physical layer realizes several network connections like ZigBee, Bluetooth or WLAN. The operating system layer provides functionality to access the physical layer and manages many other hardware and software resources and provides methods to access these resources. The application layer contains user applications which could contain modules like workflow management, user interface, custom logic and configuration details. These two layers are not part of the Hydra middleware. The middleware itself consists of three layers - the network, service and semantic layer. Each layer holds elements according to their functionality and purpose. Note, that some device elements have similar and thus similar named, counterparts among the application elements. Both, device and application elements, have a Security Manager. To express, that this manager is an orthogonal service, it is depicted vertical and covers all three middleware layers. |
Ein Verweis auf die Quelle fehlt. |
|
| [48.] Saa/Fragment 044 08 - Diskussion Bearbeitet: 21. September 2014, 21:45 Hindemith Erstellt: 7. September 2014, 09:26 (Hindemith) | Eisenhauer et al 2007, Fragment, Gesichtet, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 44, Zeilen: 8-17 |
Quelle: Eisenhauer et al 2007 Seite(n): 17, Zeilen: 13ff |
|---|---|
| Application Elements
Application Elements describe components that are usually deployed on hardware which is performance-wise capable of running the application that the solution provider creates. This means these components are meant to be running on powerful machines. They have been put together and configured to work together with other software in order to support a specific application such as building automation by a specific developer, e.g. system integrator. Device Elements Device Elements describe components that are usually deployed inside HYDRA-enabled devices, so that they could be deployed in small devices as well which have limited [resources in terms of e.g. processing power or battery life.] |
Application elements describe components that are usually deployed on hardware which is performance-wise capable of running the application that the solution-provider creates. This means these components are meant to be run on powerful machines. They have been put together and configured to work together with other software in order to support a specific application such as building automation by a specific developer e.g. system integrator.
Device elements describe components that are usually deployed inside Hydra-enabled devices so we take into account that they could be deployed in small devices which have limited resources in terms of e.g. processing power or battery life. |
Ein Verweis auf die Quelle fehlt. |
|
| [49.] Saa/Fragment 031 01 - Diskussion Bearbeitet: 21. September 2014, 21:45 Hindemith Erstellt: 6. September 2014, 20:43 (Hindemith) | Fragment, Gesichtet, Reynolds et al 2004, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 31, Zeilen: 1-8 |
Quelle: Reynolds et al 2004 Seite(n): 1, Zeilen: 24-31 |
|---|---|
| [In 2000 it was agreed that CEN, ISO and IEEE] would jointly migrate and publish this work in a single set of standards, designated as 11073 [65], for point-of-care device communication under the general leadership of IEEE. In 2003 the IEEE approved the core standards, the domain information model, the common nomenclature, the basic communications profiles and two arrangements defining the underlying transport mechanism. In early 2004, approval of these five 11073 standards within CEN and ISO was achieved, with more already in the balloting process. Alongside the core standards, application profiles have been defined for specific types of devices, such as dialysers, ventilators, monitors and infusion pumps.
[65] CEN/ISO/IEEE 11073 Medical Device Communication Standard; http:// standards.ieee.org/announcements /pr_ieeep11073.html |
In 2000 it was agreed that CEN, ISO and IEEE would jointly migrate and publish this work in a single set of standards, designated 11073, for point-of-care device communication under the general leadership of IEEE. In 2003 the IEEE approved the core standards - the domain information model, the common nomenclature, the basic communications profiles and two defining the underlying transport arrangements. In early 2004 approval of these five 11073 standards within CEN and ISO was achieved, with more already in the balloting process.
Alongside the core standards application profiles have been defined for specific types of device, such as dialysers, ventilators, monitors and infusion pumps. |
Ein Verweis auf die Quelle fehlt. Die angegebene Quelle enthält den parallelen Text nicht. |
|
| [50.] Saa/Fragment 030 41 - Diskussion Bearbeitet: 21. September 2014, 21:44 Hindemith Erstellt: 6. September 2014, 20:40 (Hindemith) | Fragment, Gesichtet, Reynolds et al 2004, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 30, Zeilen: 41-44 |
Quelle: Reynolds et al 2004 Seite(n): 1, Zeilen: 23-25 |
|---|---|
| Since 1993 a set of open CEN (European) Standards, for point-of-care device communication has been created to provide the ability to connect devices to each other freely and to exchange data between them. These standards worked to complement those of the IEEE 1073, not to be competitive. | Since 1993 a set of open CEN (European) Standards, for Point-of-care Device Communication has been created (ratified 1999) to provide the ability to connect devices to each other freely and to exchange data between them. These standards worked to complement those of the IEEE, not be competitive. |
Ein Verweis auf die Quelle fehlt. Fortsetzung auf der nächsten Seite. |
|
| [51.] Saa/Fragment 048 29 - Diskussion Bearbeitet: 21. September 2014, 21:44 Hindemith Erstellt: 5. September 2014, 10:45 (Hindemith) | Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop, Wikipedia Devices Profile for Web Services 2009 |
|
|
|
| Untersuchte Arbeit: Seite: 48, Zeilen: 29-34 |
Quelle: Wikipedia Devices Profile for Web Services 2009 Seite(n): 1 (internet Quelle), Zeilen: - |
|---|---|
| The DPWS defines a minimal set of implementation constraints to enable secure Web Service messaging, discovery, description, and eventing on resource-constrained devices. Its objectives are similar to those of UPnP but, in addition, DPWS is fully aligned with Web Services technology and includes numerous extension points allowing for seamless integration of device-provided services in enterprise-wide application scenarios. | The Devices Profile for Web Services (DPWS) defines a minimal set of implementation constraints to enable secure Web Service messaging, discovery, description, and eventing on resource-constrained devices.
Its objectives are similar to those of Universal Plug and Play (UPnP) but, in addition, DPWS is fully aligned with Web Services technology and includes numerous extension points allowing for seamless integration of device-provided services in enterprise-wide application scenarios. |
Ein Verweis auf die Quelle fehlt. |
|
| [52.] Saa/Fragment 009 28 - Diskussion Bearbeitet: 15. September 2014, 21:51 Singulus Erstellt: 7. September 2014, 14:19 (Hindemith) | Fragment, Gesichtet, Orth 2002, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 9, Zeilen: 28-33 |
Quelle: Orth 2002 Seite(n): 1, Zeilen: 35-39 |
|---|---|
| The Web Services concept aims to adopt the principles of the WWW for its vision of seamless Application-to-Application (A2A) integration, regardless of differences in programming languages and platforms, featuring the same level of openness between loosely coupled systems. The key for the broad acceptance of the WWW is that is based on open standards and consequently, Web Services are also founded on the basis of such standards. | The Web Services concept aims to adopt the principles of the WWW for its vision of seamless A2A integration, regardless of differences in programming languages and platforms, featuring the same level of openness between loosely coupled systems. The key for the broad acceptance of the WWW is that it is based on open standards. Consequently, Web Services are also founded on the basis of such standards. |
Ein Verweis auf die Quelle fehlt. |
|
| [53.] Saa/Fragment 011 01 - Diskussion Bearbeitet: 15. September 2014, 21:49 Singulus Erstellt: 7. September 2014, 12:47 (Hindemith) | Fragment, Gesichtet, Orth 2002, SMWFragment, Saa, Schutzlevel sysop, Verschleierung |
|
|
|
| Untersuchte Arbeit: Seite: 11, Zeilen: 1-16 |
Quelle: Orth 2002 Seite(n): 16, Zeilen: 15ff |
|---|---|
| Service
The service is an implementation of a software module deployed on a network accessible platform provided by the service provider to be invoked by a service requester. Service Description The service description contains the details of the interface and implementation of the service. The service interface description comprises information about the operations and their signatures provided by a service; along with the protocol used for communication with the Web Service. The service implementation description contains information about the location where the service is exposed, i.e. the endpoint address of the service. The service provider publishes the complete service description to a service registry to make the service accessible to the service requestors. It includes the data types, operations, binding information and network location of the service, as provided by the service interface and implementation descriptions. Client Application This is the software application implemented by the service requestor to use the functionality of the Web Service by invoking its operations at runtime. |
• Service: This is the implementation of a software module deployed on a network-accessible platform provided by the Service Provider to be invoked by a Service Requestor.
• Service Description: The service description contains the details of the interface and implementation of the service. The service interface description comprises information about the operations provided by a service, as well as their parameters. It can be compared with the signature of a method. Additionally, the protocol used for communication with the Web Service is described. The service implementation description contains information about the location where the service is exposed, i.e. the network address of the endpoint providing the service. The complete service description is published to a Service Registry by the Service Provider to make the service accessible to Service Requestors. It includes the service's data types, operations, binding information and network location, as provided by the service interface and implementation descriptions. It could also include information about the Service Provider, service and provider categorization and other metadata to facilitate discovery and utilization by the Service Requestor. • Client Application: This is the application implemented by the Service Requestor that uses the functionality of the Web Service and invokes it at runtime. |
Ein Verweis auf die Quelle fehlt. |
|
| [54.] Saa/Fragment 016 31 - Diskussion Bearbeitet: 15. September 2014, 21:48 Singulus Erstellt: 6. September 2014, 23:40 (Graf Isolan) | Cabral et al 2004, Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 16, Zeilen: 31-32 |
Quelle: Cabral et al 2004 Seite(n): 225-226, Zeilen: 225:38-39 - 226:1-2 |
|---|---|
| 2.4 Semantic Web Services
Whilst promising to revolutionize e-Commerce and enterprise-wide integration, current standard technologies for Web Services, i.e. WSDL provide only syntactic-level descrip[tions of their functionalities, without any formal definition to what the syntactic definitions might mean.] |
[Seite 225]
Whilst promising to revolutionize eCommerce and enterprise-wide integration, current standard technologies for Web services (e.g. WSDL [6]) provide only syntac- [Seite 226] tic-level descriptions of their functionalities, without any formal definition to what the syntactic definitions might mean. |
Ohne Hinweis auf eine Übernahme. Auf der nächsten Seite wird diese fortgesetzt (vgl. Fragment 017 01). |
|
| [55.] Saa/Fragment 016 01 - Diskussion Bearbeitet: 15. September 2014, 21:44 Singulus Erstellt: 6. September 2014, 09:48 (Graf Isolan) | Cabral et al 2004, Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 16, Zeilen: 1-24 |
Quelle: Cabral et al 2004 Seite(n): 229-230, Zeilen: 229: 18ff - 230: 1ff |
|---|---|
| [Figure 2.3: General stack of Semantic Web enabling standards]
The Semantic Web users will be able to do more accurate searches of the information and the services they need from the tools provided. The Semantic Web provides the necessary infrastructure for publishing and resolving ontological descriptions of terms and concepts. In addition, it provides the necessary techniques for reasoning about these concepts, as well as resolving and mapping between ontologies, thus enabling semantic interoperability of Web Services through the identification and mapping of semantically similar concepts. Fig. 2.3 shows the general stack of Semantic Web enabling standards. Ontologies have been developed within the Semantic Web research community in order to facilitate knowledge sharing and reuse. They provide greater expressiveness when modeling domain knowledge and can be used to communicate this knowledge between people and heterogeneous and distributed application systems. As with Web Services, Semantic Web enabling standards fit into a set of layered specifications built on the foundation of URIs and XML Schema. The current components included in the Semantic Web framework are RDF [39], RDF Schema (RDF-S) [40] and the Web Ontology Language (OWL) [41]. These standards build up a rich set of constructs for describing the semantics of online information sources. RDF is an XML-based standard from W3C for describing resources on the Web. RDF introduces a little semantics to XML data by allowing the representation of objects and their relations through properties. RDF-Schema is a simple type system, which provides information (metadata) for the interpretation of the statements given in RDF data. The OWL facilitates greater machine interpretability of Web contents than RDF and RDF Schema by providing a much richer set of constructs for specifying classes and relations. OWL has evolved from existing ontologies languages and specifically from DAML+OIL [42]. [39] Klyne, G., et al. Resource description framework (RDF): Concepts and Abstract Ssyntax, W3C recommendation 2004, http://www.w3.org/TR/rdf-concepts/ [40] RDF Schema Description Language (RDF-S); http://www.w3.org/TR/rdf-schema/ [41] Web Ontology Language (OWL); http://www.w3.org/2004/OWL/ [42] DAML+OIL Ontology Markup Language; http://www.daml.org |
Semantic Web users will be able to do more accurate searches of the information and the services they need from the tools provided.
The Semantic Web provides the necessary infrastructure for publishing and resolving ontological descriptions of terms and concepts. In addition, it provides the necessary techniques for reasoning about these concepts, as well as resolving and mapping between ontologies, thus enabling semantic interoperability of Web Services through the identification (and mapping) of semantically similar concepts. [Fig. 3. Semantic Web Enabling standards] Ontologies have been developed within the Knowledge Modelling research community [11] in order to facilitate knowledge sharing and reuse. They provide greater expressiveness when modelling domain knowledge and can be used to communicate this knowledge between people and heterogeneous and distributed application systems. [Seite 230] As with Web Services, Semantic Web enabling standards fit into a set of layered specifications (fig. 3) built on the foundation of URIs and XML Schema. The current components of the Semantic Web framework are RDF [13], RDF Schema (RDF-S) [3] and the Web Ontology Language – OWL [4]. These standards build up a rich set of constructs for describing the semantics of online information sources. RDF is a XML-based standard from W3C for describing resources on the Web. RDF introduces a little semantics to XML data by allowing the representation of objects and their relations through properties. RDF-Schema is a simple type system, which provides information (metadata) for the interpretation of the statements given in RDF data. The Web Ontology language – OWL will facilitate greater machine interpretability of Web content than RDF and RDF Schema by providing a much richer set of constructs for specifying classes and relations. OWL has evolved from existing ontologies languages and specifically from DAML+OIL [12]. 3. Brickley D., Guha R.V. (eds.): RDF Vocabulary Description Language 1.0: RDF Schema, W3C Proposed Recommendation (work in progress). http://www.w3.org/TR/rdf-schema/. (2003) 4. Bechhofer, S., Dean, M., Van Harmelen, F., Hendler, J., Horrocks, I., McGuinness, D., Patel-Schneider, P., Schreiber, G., Stein, L.: OWL Web Ontology Language Reference, W3C Proposed Recommendation (work in progress). http://www.w3.org/TR/owl-ref/. (2003) 12. Joint US/EU ad hoc Committee. Reference Description of the DAML-OIL Ontology Markup Language. http://www.daml.org/2001/03/reference. (2001) 13. Klyne, G., D., Carroll, J.J. (eds.): Resource Description Framework (RDF): Concepts and Abstract Syntax. W3C Proposed Recommendation (work in progress). http://www.w3.org/TR/rdf-concepts/. (2003) |
Figure 2.3 stimmt mit Fig. 3 der Vorlage überein. Ohne Hinweis auf eine Übernahme, obwohl auch die Texte weitgehend identisch sind. |
|
| [56.] Saa/Fragment 015 38 - Diskussion Bearbeitet: 15. September 2014, 21:43 Singulus Erstellt: 5. September 2014, 22:53 (Graf Isolan) | Cabral et al 2004, Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 15, Zeilen: 38-41 |
Quelle: Cabral et al 2004 Seite(n): 229, Zeilen: 9-13 |
|---|---|
| 2.3 Semantic Web
The Semantic Web [38] is a vision of a Web of meaningful contents and services, which can be interpreted by computer programs. It can also be seen as a vast source of information, which can be modeled with the purpose of sharing and reusing knowledge. [38] T. Berners-Lee, J. Hendler and O. Lassila; The Semantic Web, Scientific American 284(5):34-43, 2001 |
3 The Semantic Web
The Semantic Web is a vision of a Web of meaningful contents and services, which can be interpreted by computer programs (see for example [1]). It can also be seen as a vast source of information, which can be modelled with the purpose of sharing and reusing knowledge. 1. Berners-Lee, T. Hendler, J., Lassila, O.: The Semantic Web. Scientific American, Vol. 284 (4). (2001) 34-43 |
Ohne Hinweis auf eine Übernahme. |
|
| [57.] Saa/Fragment 017 01 - Diskussion Bearbeitet: 14. September 2014, 17:18 Singulus Erstellt: 4. September 2014, 23:47 (Graf Isolan) | Cabral et al 2004, Fragment, Gesichtet, KomplettPlagiat, SMWFragment, Saa, Schutzlevel sysop |
|
|
|
| Untersuchte Arbeit: Seite: 17, Zeilen: 1-18 |
Quelle: Cabral et al 2004 Seite(n): 225-226, Zeilen: 225:38-39 - 226:1-19 |
|---|---|
| [Whilst promising to revolutionize e-Commerce and enterprise-wide integration, current standard technologies for Web Services, i.e. WSDL provide only syntactic-level descrip]tions of their functionalities, without any formal definition to what the syntactic definitions might mean. In many cases, Web Services offer little more than a formally defined invocation interface, with some human oriented meta-data that describes what the service does, and which organization developed it, i.e. through UDDI [35] descriptions. The software applications may invoke Web Services using a common, extendible communication framework, i.e. SOAP [33]. However, the lack of machine-readable semantics necessitates human intervention for automated service discovery and composition within open systems, thus hampering their usage in complex business contexts.
Semantic Web Services (SWS) [44] relax this restriction by augmenting Web Services with rich formal descriptions of their capabilities, thus facilitating automated composition, discovery, dynamic binding, and invocation of services within an open environment. A prerequisite to this, however, is the emergence and evolution of the Semantic Web [38], which provides the infrastructure for the semantic interoperability of Web Services. Web Services will be augmented with rich formal descriptions of their capabilities, such that they can be utilized by software applications or other services without (or less) human assistance or highly constrained agreements on interfaces or protocols. Thus, SWSs have the potential to change the way knowledge and business services are consumed and provided on the current Web. [33] SOAP 1.2 Part 1, W3C Working Draft; http://www.w3.org/TR/soap12-part1/ [35] Universal Description, Discovery and Integration specifications; http://www.uddi.org/specification.html [38] T. Berners-Lee, J. Hendler and O. Lassila; The Semantic Web, Scientific American 284(5):34-43, 2001 [44] Semantic Web Services; http://www.daml.org/services/ |
[Seite 225]
Whilst promising to revolutionize eCommerce and enterprise-wide integration, current standard technologies for Web services (e.g. WSDL [6]) provide only syntac- [Seite 226] tic-level descriptions of their functionalities, without any formal definition to what the syntactic definitions might mean. In many cases, Web services offer little more than a formally defined invocation interface, with some human oriented metadata that describes what the service does, and which organization developed it (e.g. through UDDI descriptions). Applications may invoke Web services using a common, extendable communication framework (e.g. SOAP). However, the lack of machine readable semantics necessitates human intervention for automated service discovery and composition within open systems, thus hampering their usage in complex business contexts. Semantic Web Services (SWS) relax this restriction by augmenting Web services with rich formal descriptions of their capabilities, thus facilitating automated composition, discovery, dynamic binding, and invocation of services within an open environment A prerequisite to this, however, is the emergence and evolution of the Semantic Web, which provides the infrastructure for the semantic interoperability of Web Services. Web Services will be augmented with rich formal descriptions of their capabilities, such that they can be utilized by applications or other services without human assistance or highly constrained agreements on interfaces or protocols. Thus, Semantic Web Services have the potential to change the way knowledge and business services are consumed and provided on the Web. 6. Christensen, E. Curbera, F., Meredith, G., Weerawarana, S. Web Services Description Language (WSDL), W3C Note 15. http://www.w3.org/TR/wsdl. (2001) |
Ohne Hinweis auf eine Übernahme. |
|